今回はtensorflow cifer10の画像分類
自前のモデルを作成する場合でも、既存のモデルを元にチューニングする場合がほとんどなので、転移学習はディープラーニングにおける汎用的なスキルです。
事前準備 必要なライブラリのインポート まずは必要なライブラリを読み込みます。
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import matplotlib.pyplot as plt
print("Tensorflow version " + tf.__version__)GPUの読み込み GPUがある場合は認識して使えるようにします。
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # Suppress TensorFlow logging (1)
tf.get_logger().setLevel('ERROR') # Suppress TensorFlow logging (2)
if tf.test.is_gpu_available():
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
print("GPUの読み込みが完了しました")
else:
print("GPUが存在していません")
device_lib.list_local_devices()
データセットの準備 データセットのダウンロード cifer10 tensorflow_datasets
(train_ds, validation_ds, test_ds),ds_info = tfds.load(
"cifar10",
split=["train[:80%]", "train[80%:]", "test"],
as_supervised=True, # Include labels
with_info=True,
)
データセットは学習用に50000枚、テスト用に10000枚あります。
print(ds_info.splits['train'].num_examples)
print(ds_info.splits['test'].num_examples)50000
10000
学習用の50000枚のうち10000枚はバリデーション用として分けました。
データセットの確認 cifar10データセットの中身を確認していきましょう。
fig = tfds.show_examples(train_ds, ds_info)
cifer10は32×32 10クラス
画像サイズとクラスを変数化しておきます。
IMAGE_SIZE = [32, 32]
CLASSES = ds_info.features["label"].names
データセットを扱いやすい形式に変換 ディープラーニングで学習できるようにデータの標準化をしておきます。
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
train_ds = train_ds.map(
normalize_img, num_parallel_calls=tf.data.AUTOTUNE)
train_ds = train_ds.cache()
train_ds = train_ds.shuffle(ds_info.splits['train'].num_examples)
train_ds = train_ds.batch(32)
train_ds = train_ds.prefetch(tf.data.AUTOTUNE)
validation_ds = validation_ds.map(
normalize_img, num_parallel_calls=tf.data.AUTOTUNE)
validation_ds = validation_ds.batch(32)
validation_ds = validation_ds.cache()
validation_ds = validation_ds.prefetch(tf.data.AUTOTUNE)
test_ds_numpy = test_ds.map(
normalize_img, num_parallel_calls=tf.data.AUTOTUNE)
test_ds_numpy = test_ds_numpy.batch(32)
test_ds_numpy = test_ds_numpy.cache()
test_ds_numpy = test_ds_numpy.prefetch(tf.data.AUTOTUNE)
モデルの作成 モデルの定義 転移学習をするためベースとなるモデルを準備します。
今回はVGG16 imagenet
base_model = tf.keras.applications.vgg16.VGG16(
weights='imagenet',
include_top=False,
input_shape=[*IMAGE_SIZE, 3]
) # VGG16
base_model.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None, 32, 32, 3)] 0
block1_conv1 (Conv2D) (None, 32, 32, 64) 1792
block1_conv2 (Conv2D) (None, 32, 32, 64) 36928
block1_pool (MaxPooling2D) (None, 16, 16, 64) 0
block2_conv1 (Conv2D) (None, 16, 16, 128) 73856
block2_conv2 (Conv2D) (None, 16, 16, 128) 147584
block2_pool (MaxPooling2D) (None, 8, 8, 128) 0
block3_conv1 (Conv2D) (None, 8, 8, 256) 295168
block3_conv2 (Conv2D) (None, 8, 8, 256) 590080
block3_conv3 (Conv2D) (None, 8, 8, 256) 590080
block3_pool (MaxPooling2D) (None, 4, 4, 256) 0
block4_conv1 (Conv2D) (None, 4, 4, 512) 1180160
block4_conv2 (Conv2D) (None, 4, 4, 512) 2359808
block4_conv3 (Conv2D) (None, 4, 4, 512) 2359808
block4_pool (MaxPooling2D) (None, 2, 2, 512) 0
block5_conv1 (Conv2D) (None, 2, 2, 512) 2359808
block5_conv2 (Conv2D) (None, 2, 2, 512) 2359808
block5_conv3 (Conv2D) (None, 2, 2, 512) 2359808
block5_pool (MaxPooling2D) (None, 1, 1, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
ベースモデルの最終層を追加して、クラス数の10
また、ベースモデルの重みを学習で変えない
# Freeze base model
base_model.trainable = False
model = tf.keras.Sequential([
# To a base pretrained on ImageNet to extract features from images...
base_model,
# ... attach a new head to act as a classifier.
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(len(CLASSES), activation='softmax')
])
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='sparse_categorical_crossentropy',
metrics=['sparse_categorical_accuracy'],
)
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 1, 1, 512) 14714688
global_average_pooling2d_2 (None, 512) 0
(GlobalAveragePooling2D)
dense_2 (Dense) (None, 10) 5130
=================================================================
Total params: 14,719,818
Trainable params: 5,130
Non-trainable params: 14,714,688
_________________________________________________________________ VGG16の重みを固定 最終層の5130個
モデル(最終層)の学習 まずは、モデルの最終層だけを学習していきます。
エポック数20です。
epochs = 20
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=3)
hist = model.fit(train_ds, epochs=epochs, validation_data=validation_ds, callbacks=[callback])
Epoch 1/20
1250/1250 [==============================] - 10s 7ms/step - loss: 1.5832 - sparse_categorical_accuracy: 0.4634 - val_loss: 1.3867 - val_sparse_categorical_accuracy: 0.5361
Epoch 2/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.3369 - sparse_categorical_accuracy: 0.5442 - val_loss: 1.3060 - val_sparse_categorical_accuracy: 0.5561
Epoch 3/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.2710 - sparse_categorical_accuracy: 0.5657 - val_loss: 1.2685 - val_sparse_categorical_accuracy: 0.5662
Epoch 4/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.2354 - sparse_categorical_accuracy: 0.5767 - val_loss: 1.2430 - val_sparse_categorical_accuracy: 0.5783
Epoch 5/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.2109 - sparse_categorical_accuracy: 0.5842 - val_loss: 1.2300 - val_sparse_categorical_accuracy: 0.5787
Epoch 6/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1927 - sparse_categorical_accuracy: 0.5894 - val_loss: 1.2131 - val_sparse_categorical_accuracy: 0.5853
Epoch 7/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1786 - sparse_categorical_accuracy: 0.5960 - val_loss: 1.2105 - val_sparse_categorical_accuracy: 0.5825
Epoch 8/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1687 - sparse_categorical_accuracy: 0.5981 - val_loss: 1.2082 - val_sparse_categorical_accuracy: 0.5845
Epoch 9/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1587 - sparse_categorical_accuracy: 0.6043 - val_loss: 1.2038 - val_sparse_categorical_accuracy: 0.5873
Epoch 10/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1518 - sparse_categorical_accuracy: 0.6035 - val_loss: 1.1926 - val_sparse_categorical_accuracy: 0.5932
Epoch 11/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1453 - sparse_categorical_accuracy: 0.6061 - val_loss: 1.1880 - val_sparse_categorical_accuracy: 0.5955
Epoch 12/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1402 - sparse_categorical_accuracy: 0.6084 - val_loss: 1.1851 - val_sparse_categorical_accuracy: 0.5943
Epoch 13/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1351 - sparse_categorical_accuracy: 0.6081 - val_loss: 1.1946 - val_sparse_categorical_accuracy: 0.5883
Epoch 14/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1313 - sparse_categorical_accuracy: 0.6095 - val_loss: 1.1943 - val_sparse_categorical_accuracy: 0.5888
Epoch 15/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1272 - sparse_categorical_accuracy: 0.6106 - val_loss: 1.1837 - val_sparse_categorical_accuracy: 0.5956
Epoch 16/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1239 - sparse_categorical_accuracy: 0.6137 - val_loss: 1.1872 - val_sparse_categorical_accuracy: 0.5913
Epoch 17/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1209 - sparse_categorical_accuracy: 0.6140 - val_loss: 1.1847 - val_sparse_categorical_accuracy: 0.5937
Epoch 18/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1192 - sparse_categorical_accuracy: 0.6138 - val_loss: 1.1787 - val_sparse_categorical_accuracy: 0.5962
Epoch 19/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1159 - sparse_categorical_accuracy: 0.6162 - val_loss: 1.1811 - val_sparse_categorical_accuracy: 0.5948
Epoch 20/20
1250/1250 [==============================] - 9s 7ms/step - loss: 1.1136 - sparse_categorical_accuracy: 0.6160 - val_loss: 1.1816 - val_sparse_categorical_accuracy: 0.5958
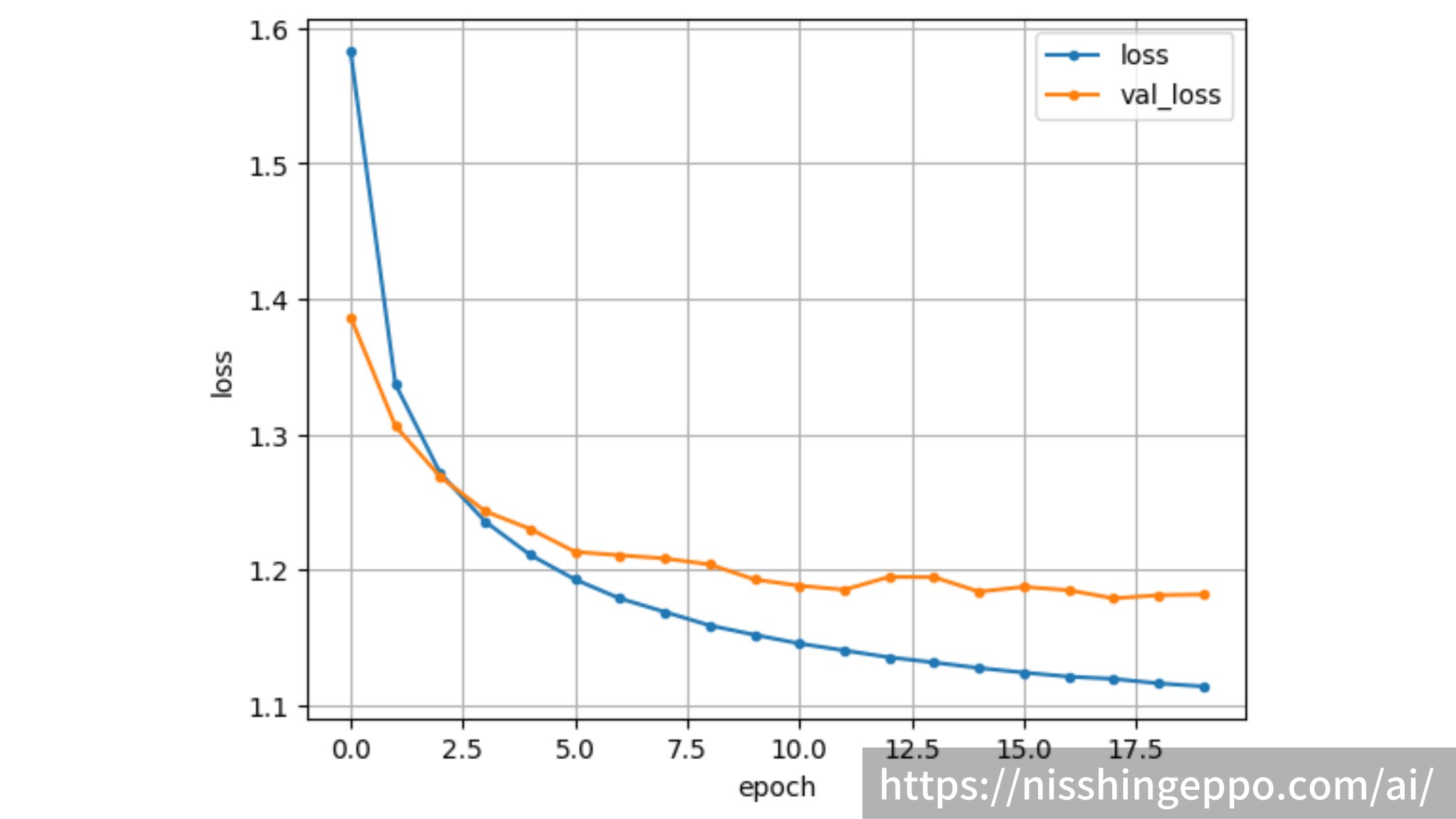
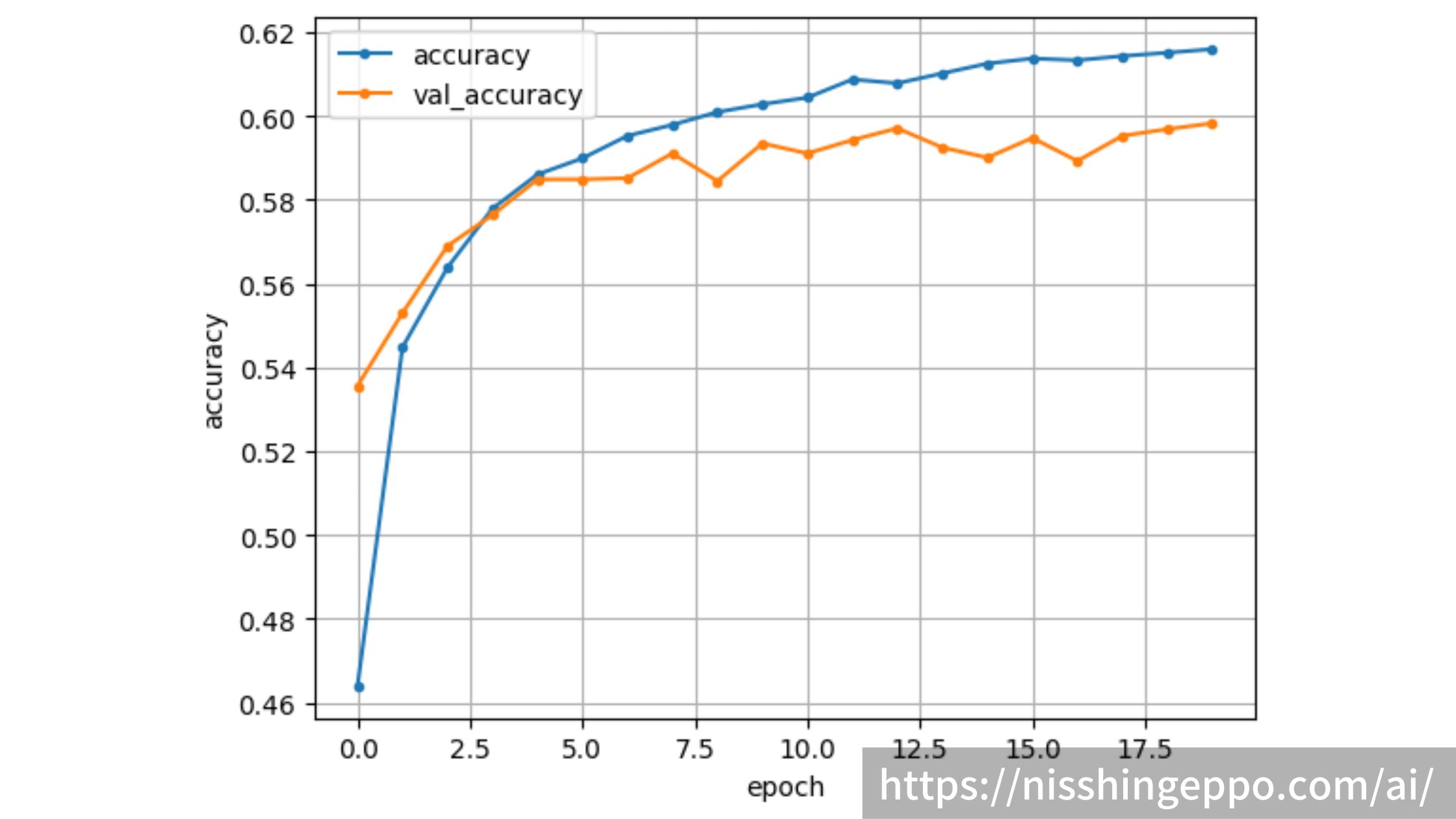
バリデーションデータで60%の正解率
エポックごとのloss関数 正解率の
まずはloss関数
# loss関数の描画
loss = hist.history['loss']
val_loss = hist.history['val_loss']
# lossのグラフ
plt.plot(range(epochs), loss, marker='.', label='loss')
plt.plot(range(epochs), val_loss, marker='.', label='val_loss')
plt.legend(loc='best', fontsize=10)
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
次に正解率
# 正解率の描画
acc = hist.history['sparse_categorical_accuracy']
val_acc = hist.history['val_sparse_categorical_accuracy']
# accuracyのグラフ
plt.plot(range(epochs), acc, marker='.', label='accuracy')
plt.plot(range(epochs), val_acc, marker='.', label='val_accuracy')
plt.legend(loc='best', fontsize=10)
plt.grid()
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
モデル(全体)の学習 ベースモデルの重みも学習できるようにして、モデル全体の学習
転移学習ではある程度の学習は終わっているので、ここでは学習率を低くして微調整
base_model.trainable = True
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-5),
loss='sparse_categorical_crossentropy',
metrics=['sparse_categorical_accuracy'],
)
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 1, 1, 512) 14714688
global_average_pooling2d (G (None, 512) 0
lobalAveragePooling2D)
dense (Dense) (None, 10) 5130
=================================================================
Total params: 14,719,818
Trainable params: 14,719,818
Non-trainable params: 0
_________________________________________________________________ 学習対象は全てのパラメータ
エポックを10として学習していきます。
epochs = 10
hist2 = model.fit(train_ds, epochs=epochs, validation_data=validation_ds, callbacks=[callback])
Epoch 1/10
1250/1250 [==============================] - 20s 15ms/step - loss: 0.8631 - sparse_categorical_accuracy: 0.6989 - val_loss: 0.7756 - val_sparse_categorical_accuracy: 0.7307
Epoch 2/10
1250/1250 [==============================] - 19s 15ms/step - loss: 0.5788 - sparse_categorical_accuracy: 0.7968 - val_loss: 0.6251 - val_sparse_categorical_accuracy: 0.7819
Epoch 3/10
1250/1250 [==============================] - 19s 15ms/step - loss: 0.4376 - sparse_categorical_accuracy: 0.8451 - val_loss: 0.6166 - val_sparse_categorical_accuracy: 0.7892
Epoch 4/10
1250/1250 [==============================] - 19s 15ms/step - loss: 0.3273 - sparse_categorical_accuracy: 0.8833 - val_loss: 0.6322 - val_sparse_categorical_accuracy: 0.7873
Epoch 5/10
1250/1250 [==============================] - 19s 15ms/step - loss: 0.2465 - sparse_categorical_accuracy: 0.9133 - val_loss: 0.6148 - val_sparse_categorical_accuracy: 0.8068
Epoch 6/10
1250/1250 [==============================] - 19s 15ms/step - loss: 0.1709 - sparse_categorical_accuracy: 0.9413 - val_loss: 0.6705 - val_sparse_categorical_accuracy: 0.8008
Epoch 7/10
1250/1250 [==============================] - 19s 15ms/step - loss: 0.1207 - sparse_categorical_accuracy: 0.9595 - val_loss: 0.6549 - val_sparse_categorical_accuracy: 0.8178
Epoch 8/10
1250/1250 [==============================] - 19s 15ms/step - loss: 0.0860 - sparse_categorical_accuracy: 0.9728 - val_loss: 0.7408 - val_sparse_categorical_accuracy: 0.8165
Epoch 9/10
1250/1250 [==============================] - 19s 15ms/step - loss: 0.0617 - sparse_categorical_accuracy: 0.9809 - val_loss: 0.7577 - val_sparse_categorical_accuracy: 0.8177
Epoch 10/10
1250/1250 [==============================] - 19s 15ms/step - loss: 0.0512 - sparse_categorical_accuracy: 0.9841 - val_loss: 0.7444 - val_sparse_categorical_accuracy: 0.8262
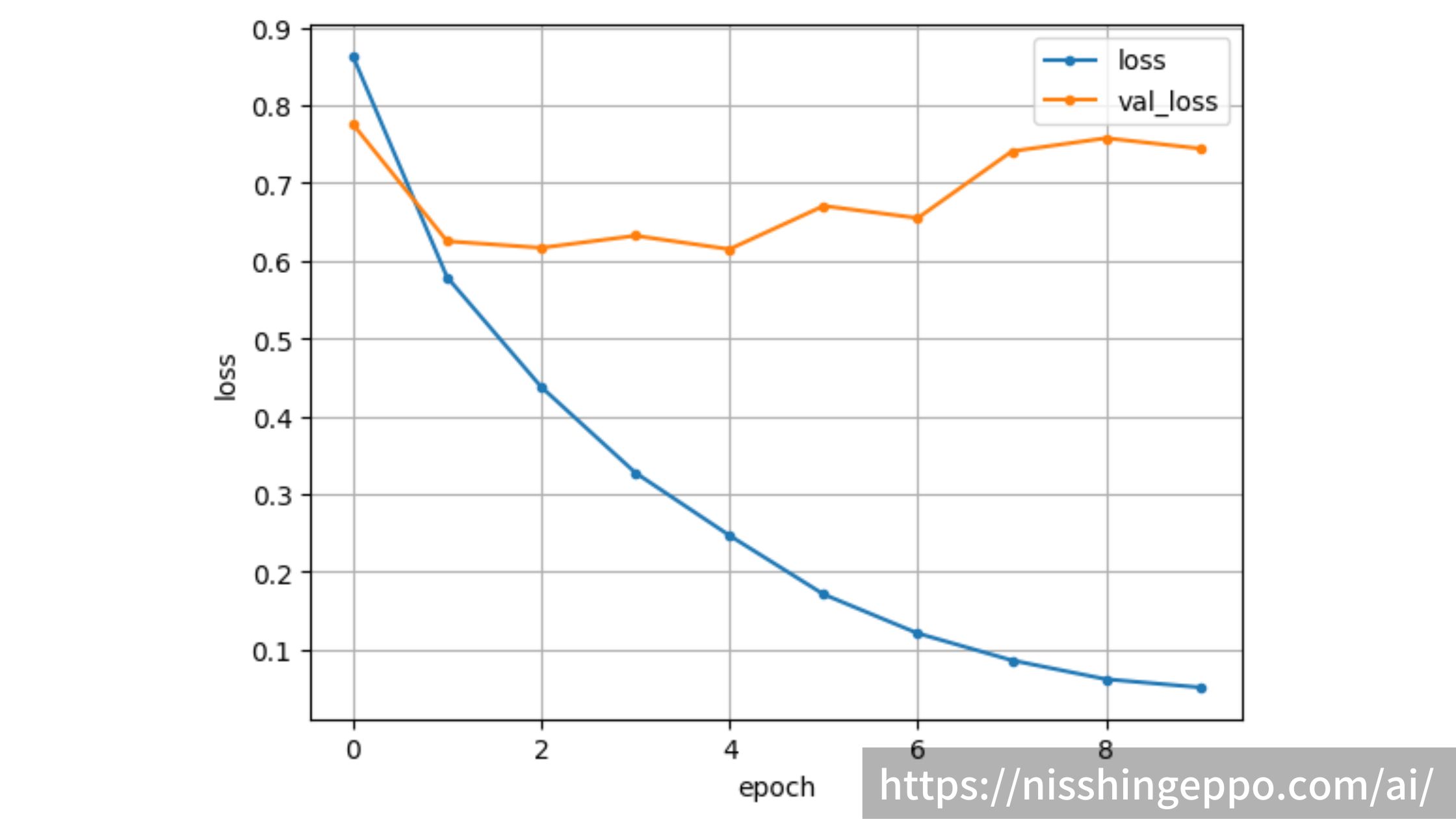
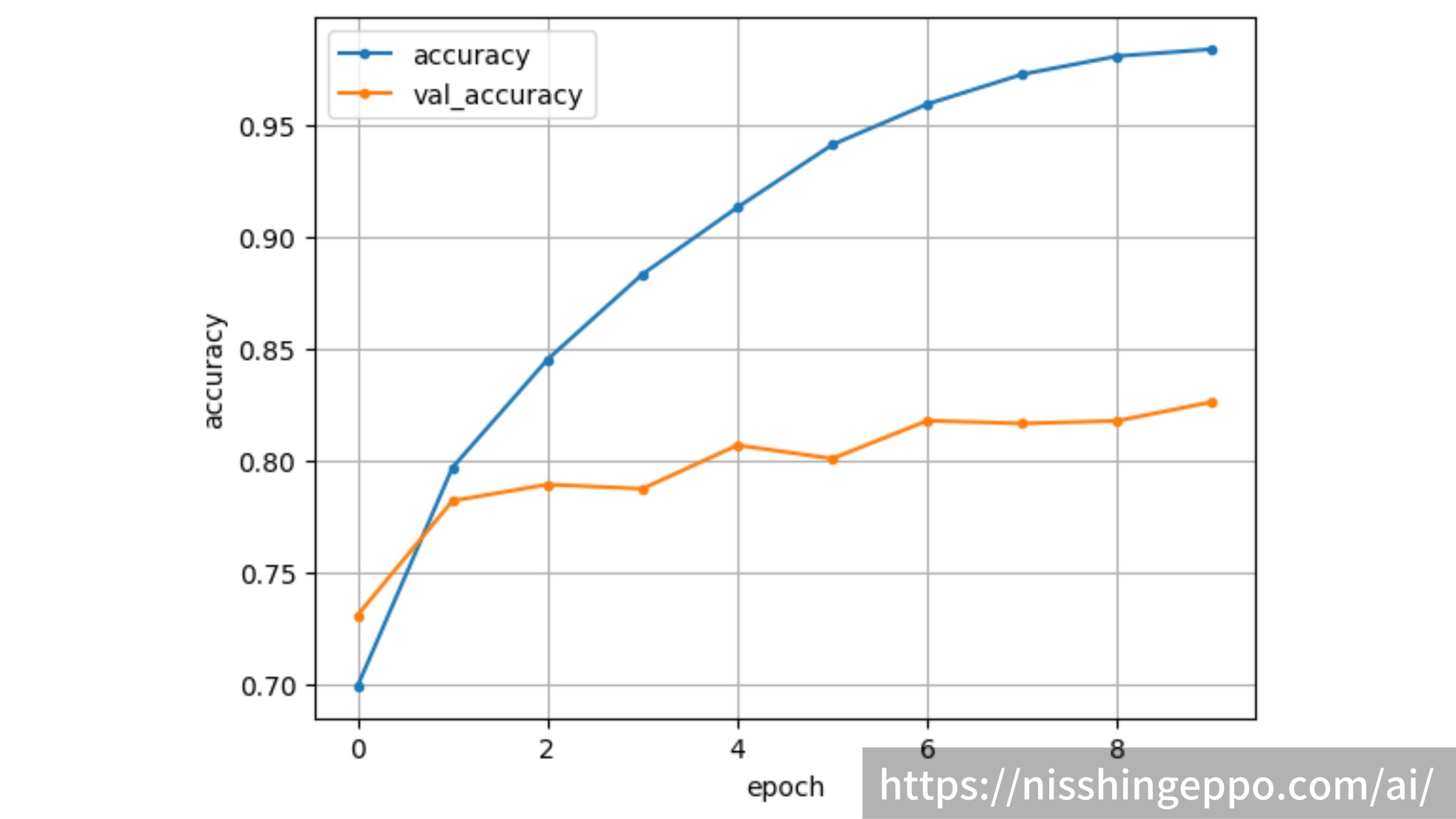
バリデーションデータで82%の正解率
エポックごとのloss関数 正解率
まずはloss関数
# loss関数の描画
loss = hist2.history['loss']
val_loss = hist2.history['val_loss']
# lossのグラフ
plt.plot(range(epochs), loss, marker='.', label='loss')
plt.plot(range(epochs), val_loss, marker='.', label='val_loss')
plt.legend(loc='best', fontsize=10)
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
次に正解率
# 正解率の描画
acc = hist2.history['sparse_categorical_accuracy']
val_acc = hist2.history['val_sparse_categorical_accuracy']
# accuracyのグラフ
plt.plot(range(epochs), acc, marker='.', label='accuracy')
plt.plot(range(epochs), val_acc, marker='.', label='val_accuracy')
plt.legend(loc='best', fontsize=10)
plt.grid()
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
テストデータの推論 テストデータの推論 完成したモデルを使ってテストデータに対して推論
predict_result = model.predict(test_ds_numpy)
print(predict_result)
[[8.4713583e-06 4.5460080e-10 4.6477892e-02 ... 1.5569612e-01
4.6203347e-11 2.0067171e-07]
[9.6759516e-01 1.4876277e-02 1.7899706e-06 ... 1.7097492e-03
1.3638774e-02 1.2169008e-06]
[5.1128139e-14 3.8003504e-16 3.1658337e-03 ... 1.6636051e-07
4.4270571e-15 7.2220372e-09]
...
[3.9835426e-04 1.4767452e-06 2.1840974e-06 ... 1.1460757e-09
9.9923503e-01 6.4742853e-06]
[4.0913835e-07 7.2732679e-12 2.8148954e-06 ... 2.2136538e-07
9.3438801e-10 1.2505372e-10]
[9.9986160e-01 3.4977507e-11 2.0911577e-05 ... 9.4836623e-06
6.8285875e-09 8.8547498e-09]] 各クラスに所属する確率が推論結果として返されます。
推論結果の確認 このままだと分かりづらいので、一番確率の高い結果
cm_predictions = np.argmax(predict_result, axis=-1)
print(cm_predictions)一枚目の画像はクラス7と予測していました。
画像を確認してみましょう。
plt.figure(figsize=(10, 10))
for i, (image, label) in enumerate(test_ds.take(9)):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image)
plt.title(f"pred:{CLASSES[cm_predictions[i]]}\n ans:{CLASSES[label]} ")
plt.axis("off")
plt.show()
きちんと予測できていることがわかりました。
まとめ tensorflow 転移学習
cifer10
独自のデータセットを使う場合でも1から学習するのではなく、転移学習を利用する
参考文献
Keras documentation: Transfer learning & fine-tuning
Keras documentation
























コメント