


















- 決定木とは何か
- 決定木のアルゴリズム
- ジニ不純度の計算方法
例えば運動会の中止の判断を決定木で表すことができます。
「雨が降っていたら中止」、「風が強かったら中止」といった条件を使って結果を判断しています。
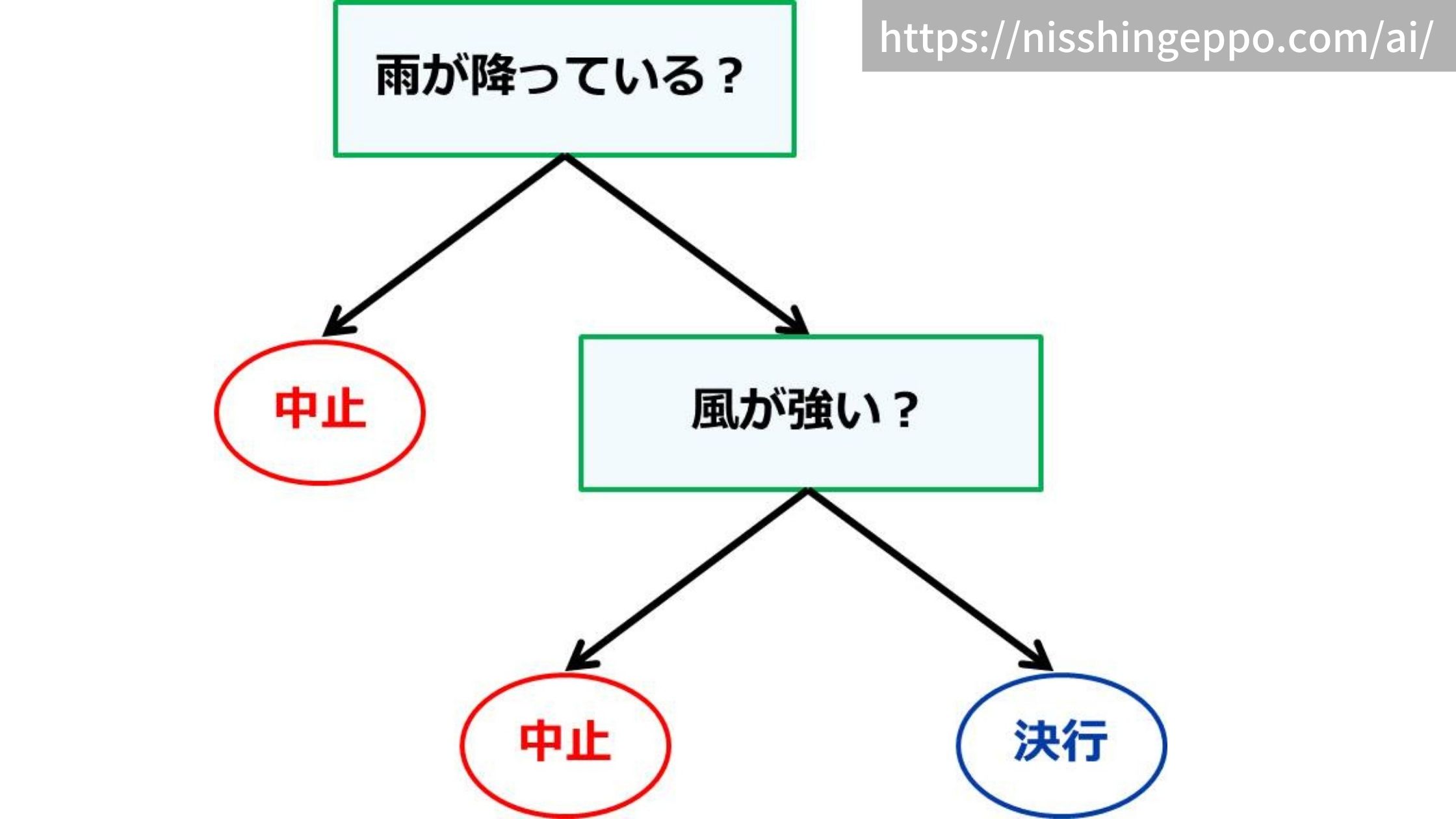
直感的でわかりやすい手法なので、日常生活でも無意識に使っているかもしれませんね。
決定木の種類
決定木は、分類木(Classification Tree)と回帰木(Regression Tree)の2種類に分けられます。

分類木はクラス分類(グループ分け)を行い、回帰木は数値の予測を行います。
例えば分類木では不動産の情報(間取り、駅からの距離、設備など)が特徴量として与えられたら、出力結果として人気がある・ないといった分類分けをする用途で使います。
一方で回帰木では、家賃がいくらかを推測してするような用途で使います。
決定木のアルゴリズム
決定木は条件分岐で問題を解く手法ですが、条件がどのように作成されているかを見ていきましょう。
- ステップ1全ての特徴量で分割を試して、不純度(うまく分けられているか)を計算する
- ステップ2不純度が一番小さい(うまく分けられた)条件を適用し、分割する
- ステップ3分割後の領域に対して、「ステップ1」「ステップ2」を繰り返す
ステップ1:不純度を計算する
不純度の種類
不純度の計算手法には様々なものが存在します。
ここでは代表的な指標であるジニ不純度について説明します。
$$ ジニ不純度 = 1 – \sum ^{c}_{t=1}p_{i}^2$$ここでcはラベル数、pはあるラベルの数をデータ数で割ったものです。
次から実際に具体例を見ていきます。
全体のデータのジニ不純度
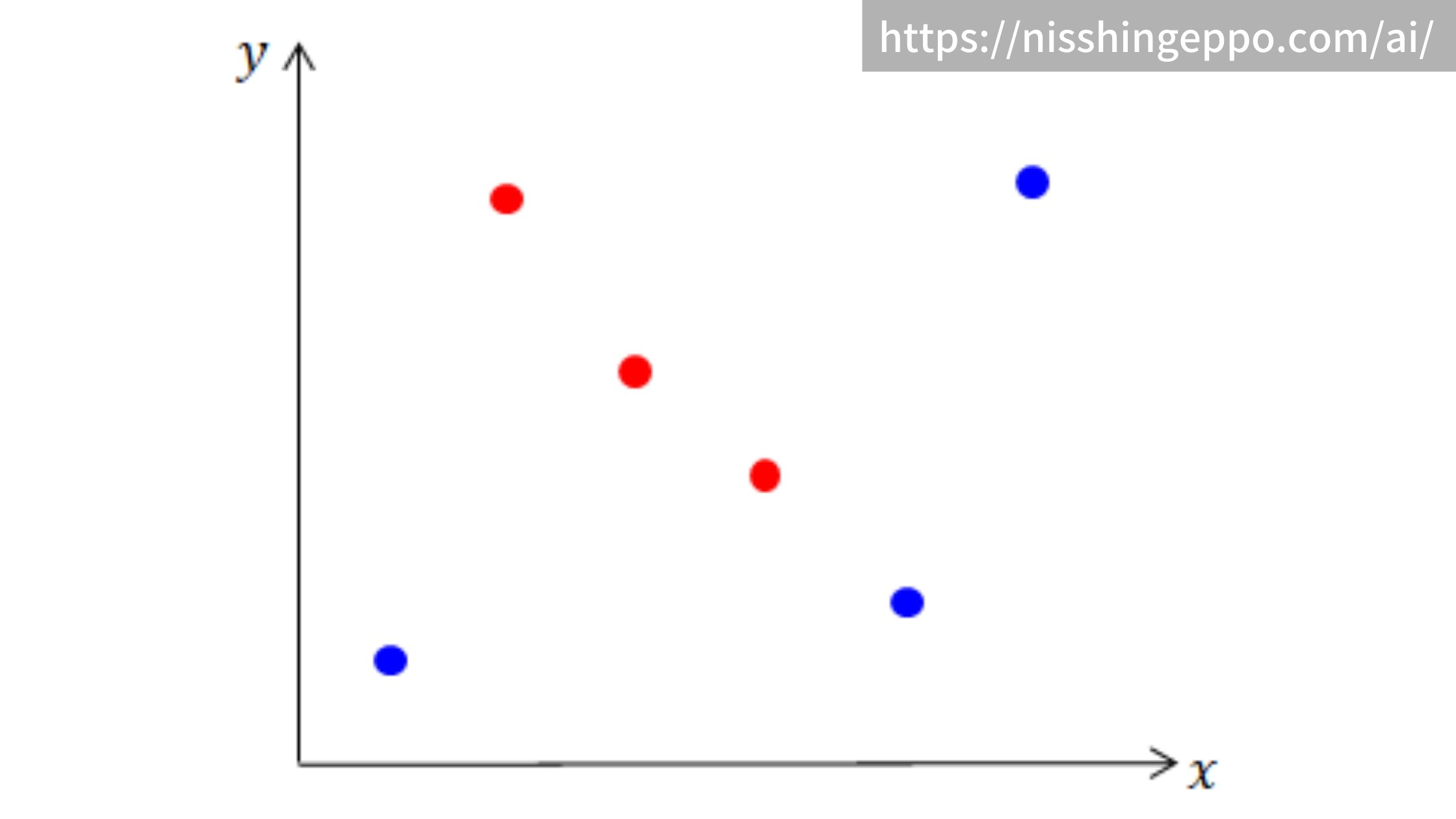
$$ ジニ不純度 = 1-\left\{ \left( \frac{3}{6}\right) ^{2}+\left( \frac{3}{6}\right) ^{2}\right\} = 0.5 $$
データを分割した場合のジニ不純度
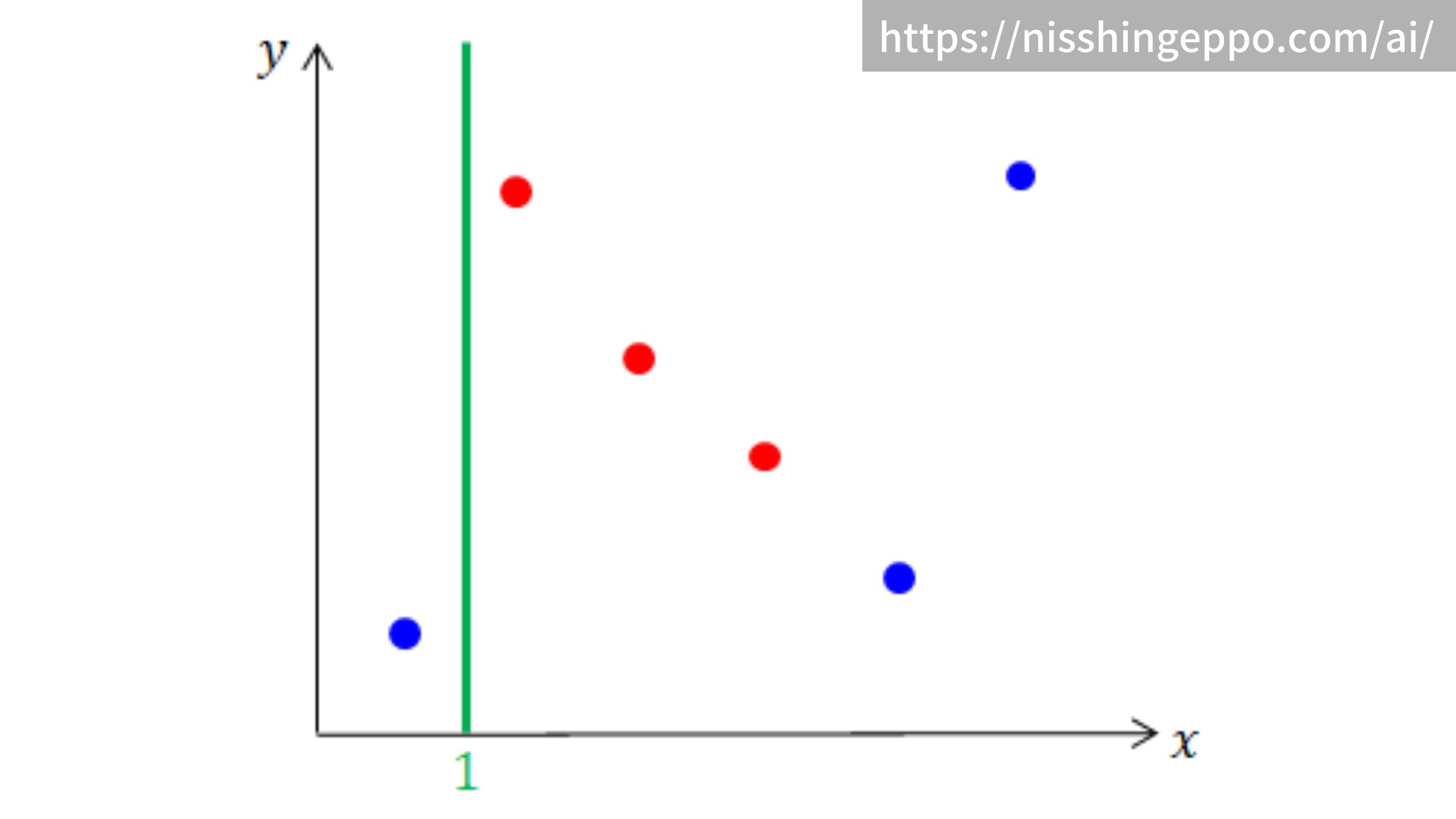
分割した場合は各領域ごとにジニ不純度を計算して、加重平均を取ります。
$$ ジニ不純度 = \frac{1}{6}\left\{ 1-\left( \frac{1}{1}\right) ^{2}\right\} + \frac{5}{6}\left\{ 1-\left\{ \left( \frac{3}{5}\right) ^{2} + \left( \frac{2}{5}\right) ^{2}\right\}\right\}= 0.4 $$
分割位置をもう少し右にずらす
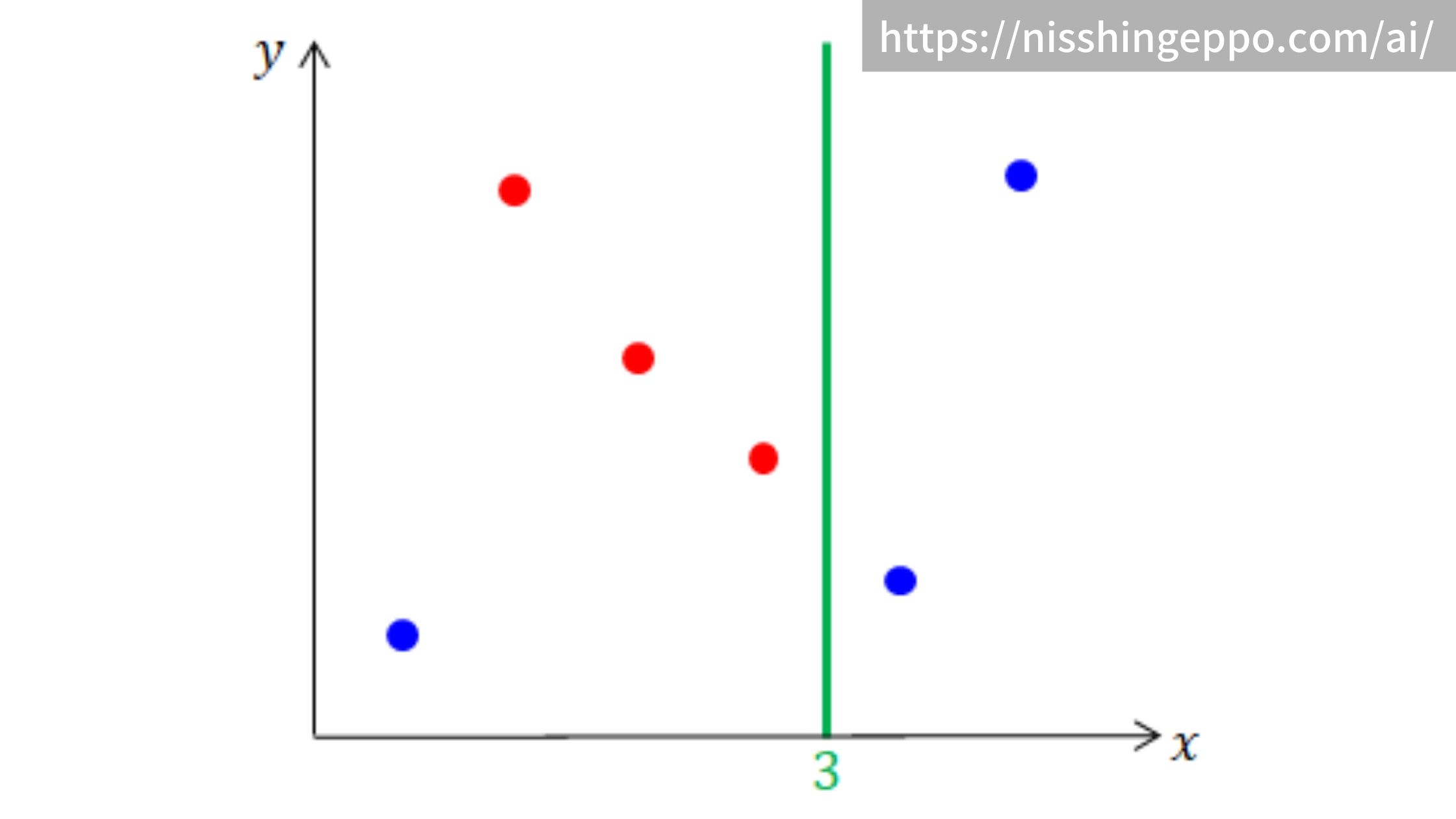
$$ ジニ不純度 = \frac{4}{6}\left\{ 1-\left\{ \left( \frac{3}{4}\right) ^{2}+\left( \frac{1}{4}\right) ^{2}\right\}\right\} + \frac{2}{6}\left\{ 1- \left( \frac{2}{2}\right) ^{2}\right\}= 0.25 $$
ステップ2:不純度が一番小さい条件を適用
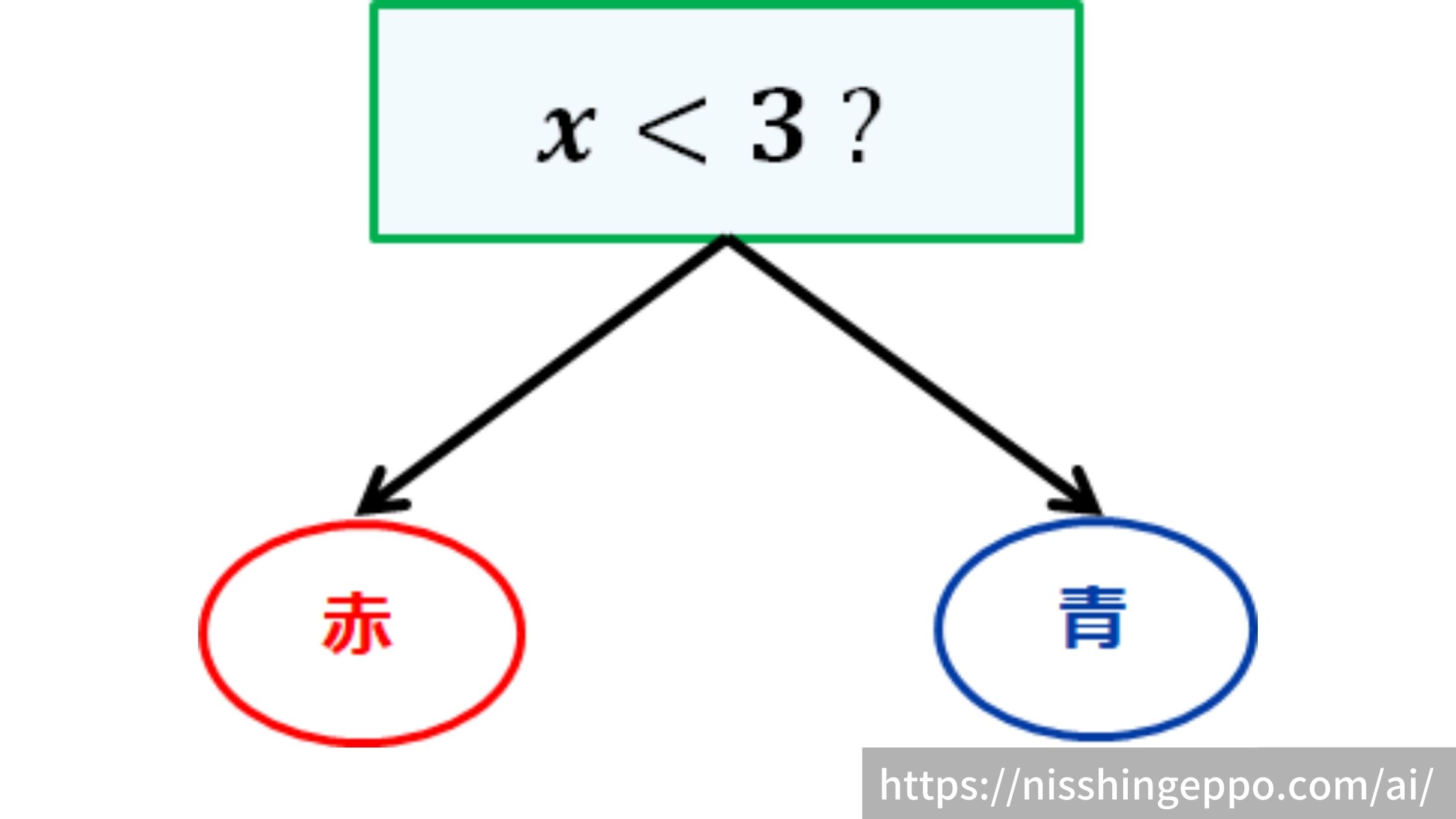
ステップ1で計算したジニ不純度が一番小さいx=3の分割を適用します。
このとき決定木の分岐が1段作成されました。
ステップ3:分割を繰り返す
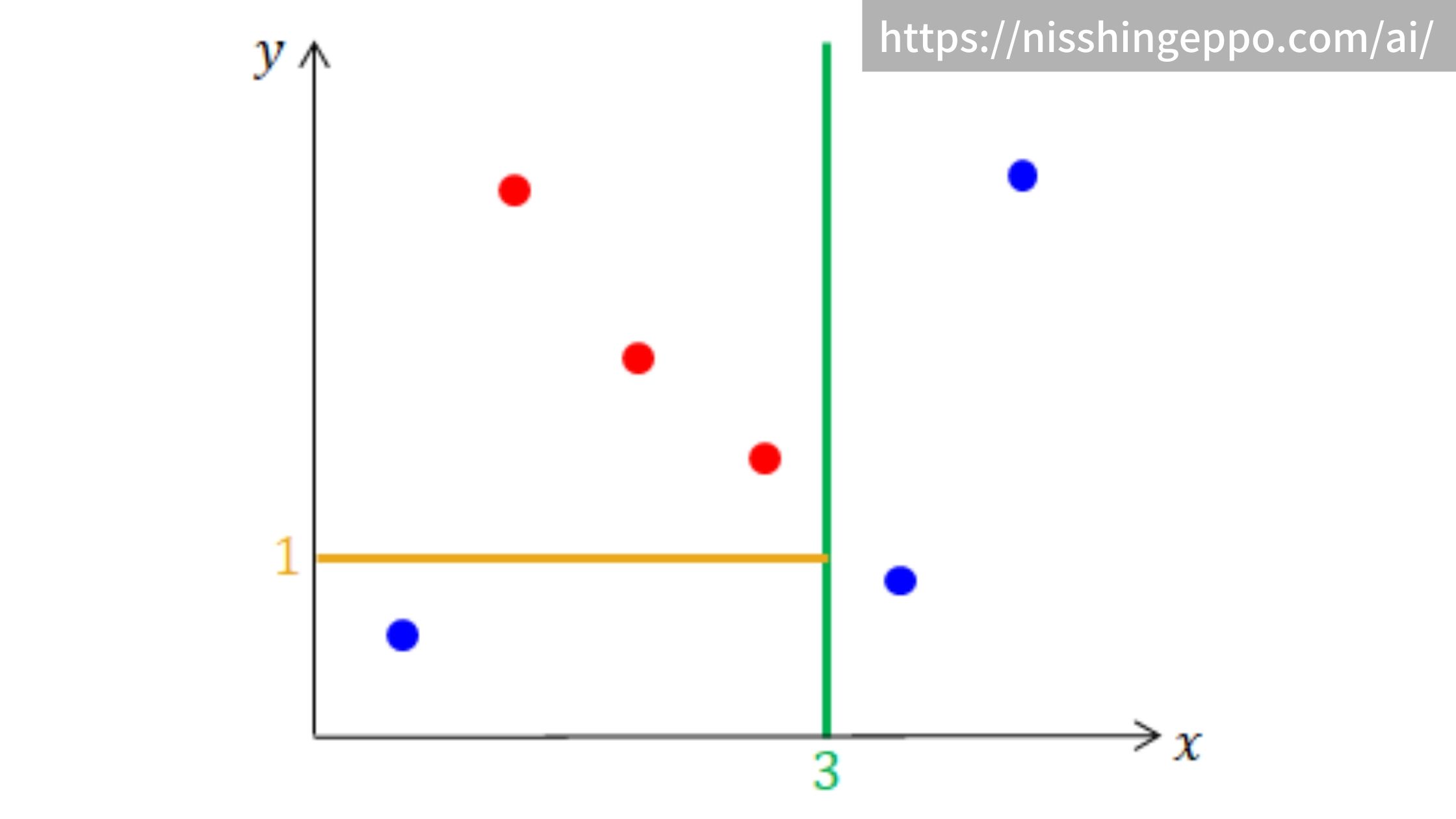
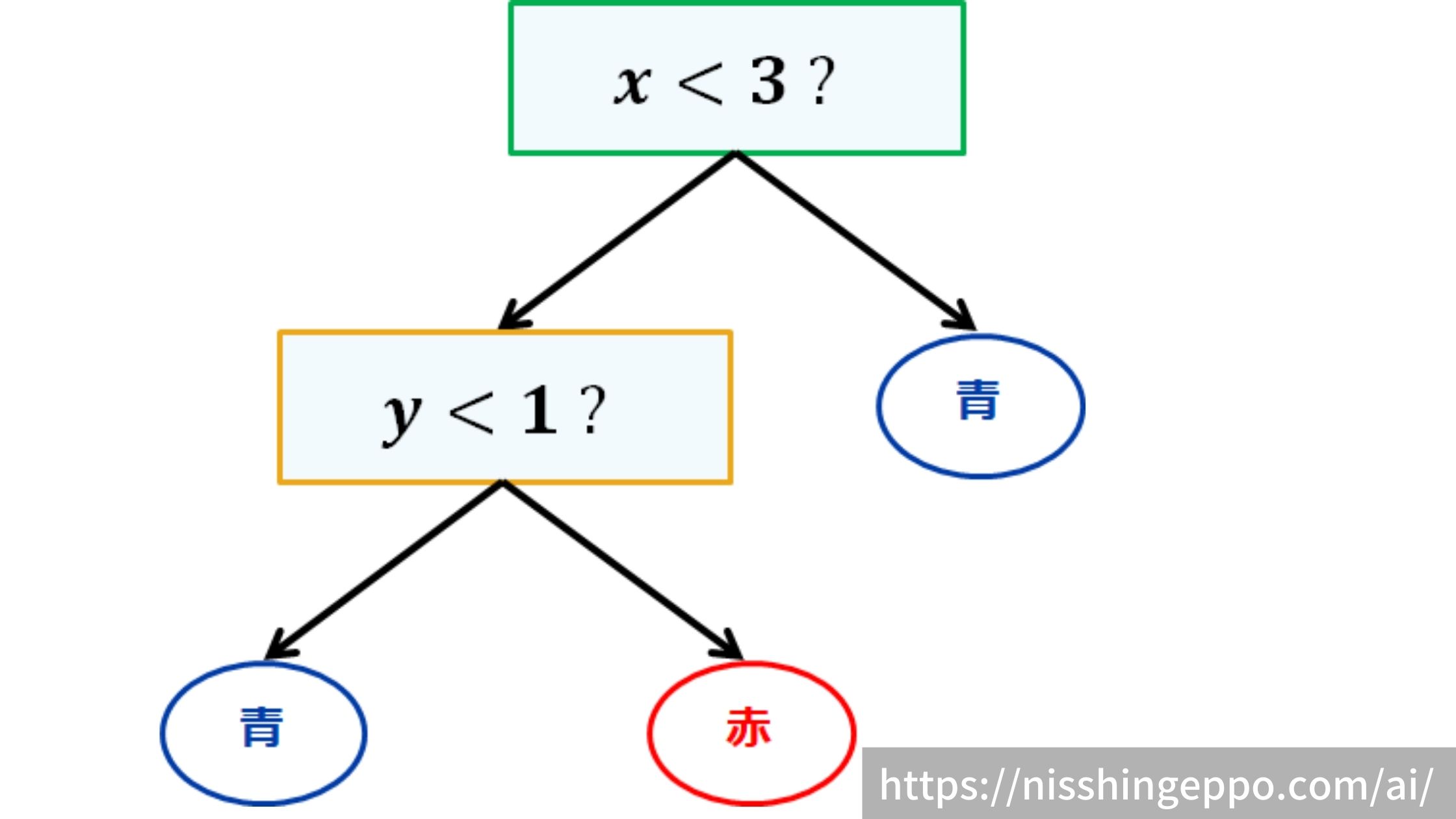
ステップ1と2を繰り返して、更に細かく分割していきます。
どのくらい繰り返すか(決定木の深さ)はユーザが指定するハイパーパラメータとなります。
繰り返していくとこのように分割されて、決定木が深くなっていきます。
まとめ
決定木とは、条件分岐によって問題を解く機械学習の手法です。
回帰と分類どちらの問題も解くことができます。
決定木の学習は、不純度を計算して最小になるような分割を探索するものです。
出力結果の因果関係がわかりやすいアルゴリズムなので、適用しやすいという特徴があります。
参考文献



コメント