

















- kNN(k-Nearest Neighbor method)とは何か
- kNNのアルゴリズム
- kNNのメリット・デメリット
- pythonでのkNNの実装
kNN(k-Nearest Neighbor method)とは?
kNN(k-Nearest Neighbor method)は、覚えたデータを利用するというモデルです。
「学習データでパラメータの最適化を行う」という過程はなく、いきなり本番データの分析を行っていきます。
また、kNNは分類と回帰のどちらの問題にも利用することができます。
kNNは、他の機械学習手法とは異なり学習フェーズが存在しません。
事前に学習して作ったモデルを適応せず、推定フェーズで学習データと未知のデータの関係性を計算していきます。
kNNは、すぐに推定ができて様々な問題に適用できる汎用的な手法なんだよ。
kNN(k-Nearest Neighbor method)のアルゴリズム
kNNでは既存のデータを覚えておき、未知のデータと似ている既存のデータを利用する単純なアルゴリズムになっています。
既存のデータ(学習データ)をベクトル空間にプロットしておき、未知のデータと近いデータをk個取得して多数決を行うアルゴリズムです。
具体的には次のような動作をしていきます。
kNNのアルゴリズム
- 既存のデータ(学習データ)をベクトル空間にプロット
- 未知データと既存データの距離を計算する
- 未知データと近いデータをk個抽出する
- 抽出したk個のデータで多数決をして、結果として出力する
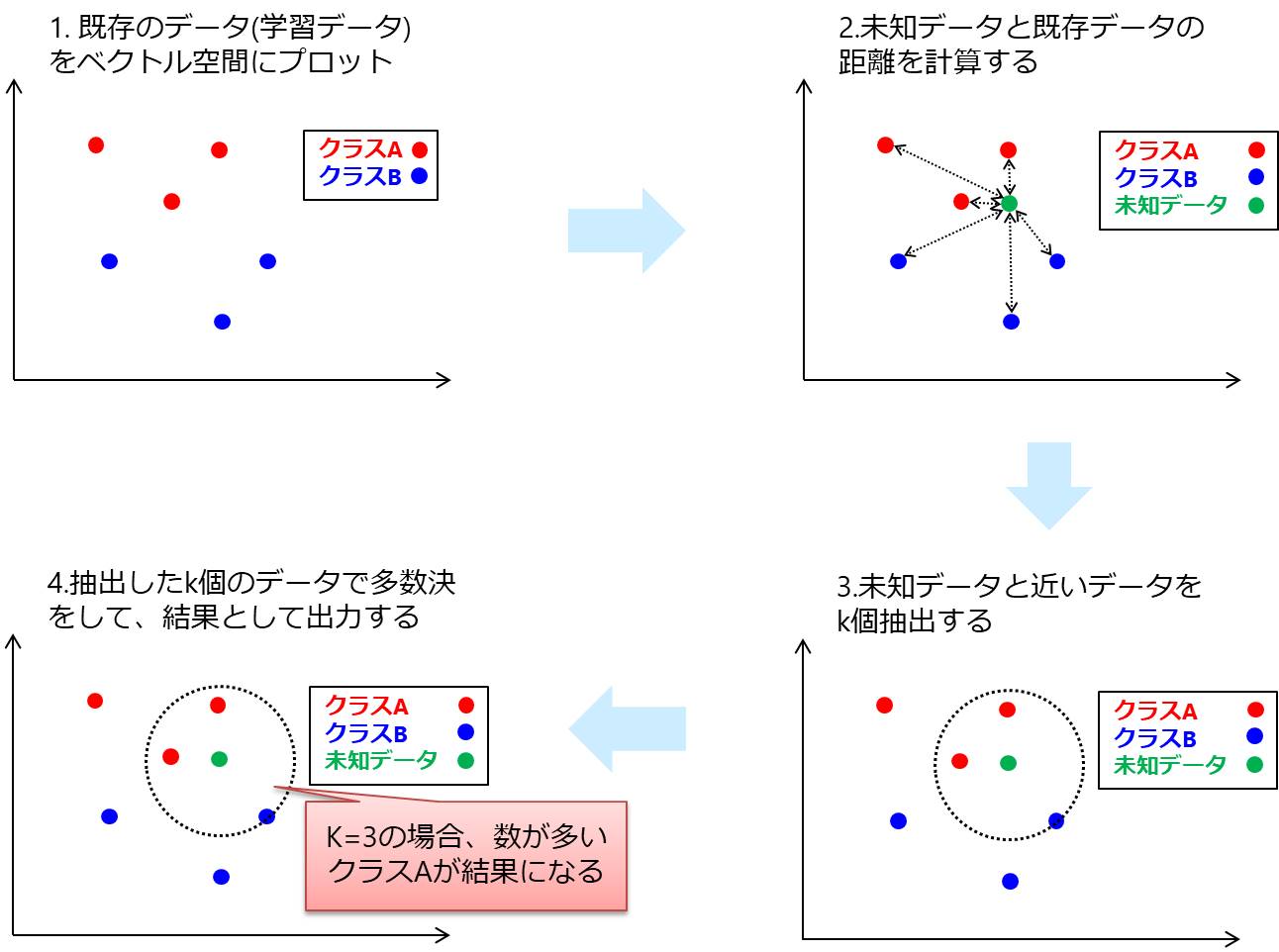
抽出する近傍点の数kはハイパーパラメータです。
2値分類のときはkを奇数にして多数決が同点にならないようにするのが一般的です。
kNNは既存の似ているデータで多数決を取る単純なモデルだね。
アルゴリズムがわかりやすいから、どうやって結果が得られたか後から説明することもできるね。
kNN(k-Nearest Neighbor method)のメリット・デメリット
kNNがどんな処理をしているのかわかってもらえたと思います。
次にkNNのアルゴリズムにはどんなメリットやデメリットがあるか見ていきましょう。
kNNのメリット
knnのアルゴリズムには学習フェーズが存在しないので、データを準備したらすぐに解析を始めることができます。
また、アルゴリズムがシンプルなので予測結果が人間にも分かりやすく、出力した結果を説明したり分析することができます。
予測結果がブラックボックスにならないというだけでも、他の機械学習手法とは違う大きなメリットになっています。
kNNのデメリット
knnでは推定のフェーズですべての計算を行います。
推定データと学習データ全ての距離を計算する必要があるので計算量がO(N)でデータ量に伴って計算量がどんどん増えてしまいます。
また、全てのデータの距離を記憶しておく必要があるので、大量のメモリも必要となります。
学習データを木構造を用いて記憶することで効率的に計算することができますが、一般的に大規模なデータセットにkNNは向きません。
kNNは「データ量を増やせば、未知のデータの近くには学習データが見つかる」という過程を前提としています。
しかし、高次元のデータでは必ずしも成立しないので、音声データや画像データに対しては他の手法を検討する必要があります。
kNN(k-Nearest Neighbor method)をpythonで実装
必要ライブラリのインポート
from sklearn.datasets import make_moons from sklearn.neighbors import kNeighborsClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
データの生成
#データ生成 X, y = make_moons(noise=0.3) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
kNN(k-Nearest Neighbor method)のモデルで学習する
#kNNで分類する model = kNeighborsClassifier() model.fit(X_train, y_train)#学習 y_pred = model.predict(X_test)#推定 accuracy_score(y_pred, y_test)
結果は
0.9333333333
となり、93%の分類精度となりました。
まとめ
kNN(k-Nearest Neighbor method)とは何かをまとめると以下の3つの特徴を持つモデルです。
- 未知のデータと学習データの距離を用いたモデル
- 分類と回帰問題のどちらにも用いることができるモデル
- シンプルなモデルが元になっているので、結果の透明性があるモデル


コメント