


















- ランダムフォレスト(Random forest)とは何か
- ランダムフォレスト(Random forest)のアルゴリズム
- ランダムフォレストに決定木が使われる理由
- pythonでのナイーブベイズの実装
ランダムフォレスト(Random forest)とは?
ランダムフォレストは、決定木を複数個利用し、多数決を取って予測するモデルです。
ランダムフォレストは分類と回帰のどちらの問題にも利用することができます。
言葉だけだと分かりづらいので、以下にランダムフォレストの分類のイメージを示します。
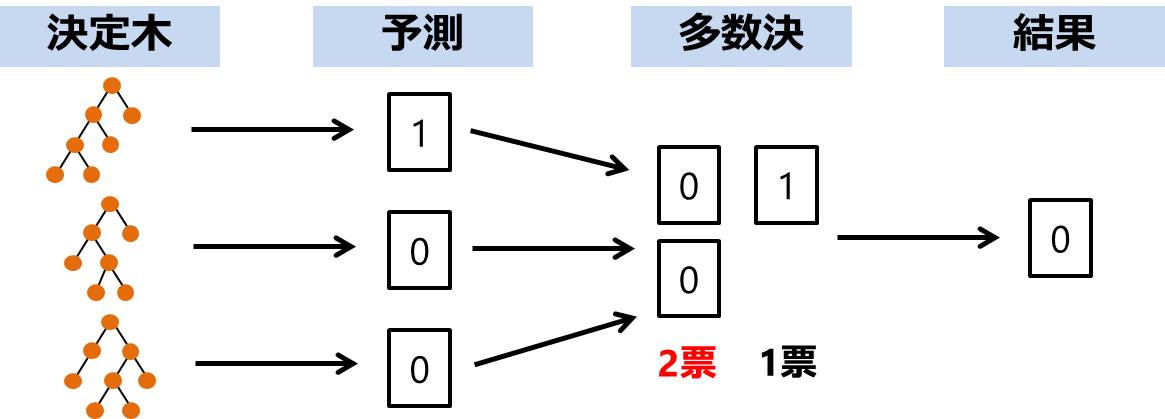
まず、決定木のモデルをたくさん用意し、それぞれに問題の予測をさせます。
決定木が出した予想を集計し、多数決(一番予測されたものの多かった答え)の結果がランダムフォレストの予測です。
このように複数の学習モデルの結果を組み合わせるテクニックをアンサンブル学習といいます。
ランダムフォレストは、一人で考えて結果を出すのではなく、みんなで相談して多数決で答えを出す民主主義な手法だね。
そもそも決定木とはなんだっけ??という人は下の記事を参考にしてみてください。

ランダムフォレストのアルゴリズム
ランダムフォレストでは、アンサンブル学習のバギング(ブートストラップ集約)を使っています。
アンサンブル学習を詳しく知りたい人は以下の記事をご覧ください。

具体的なアルゴリズムは3ステップで行われます。
- 学習データからN個のデータ集合を取り出す(ブートストラップ法 + 特徴量の選択)
- 取り出したデータ集合を使って決定木をN個生成する
- N個の決定機の予測値の平均を取って、最終的な予測値とする
1. 学習データからN個のデータ集合を取り出す(ブートストラップ法 + 特徴量の選択)
決定木をN個作るために学習データをN個に分けます。
学習データにブートストラップ法と特徴量の選択の2段階でデータ群を作成していきます。

ブートストラップ法では学習データをランダムに抽出(重複可)してデータ群を作成し、
その後に特徴量をランダムに選択することで多様性のあるデータ群を作成することが可能です。
データを分けることで、多種多様な決定木を作るんだね。
同じデータ群から決定木を作ってしまうと似たような推測をするモデルができてしまい、多数決を取る意味がなくなってしまうよ。
2. 取り出したデータ集合を使って決定木をN個生成する
取り出したデータ集合に対してそれぞれ決定木を作成します。
決定木の構築アルゴリズムは以下の記事に詳細が説明されています。

3. N個の決定機の予測値の平均を取って、最終的な予測値とする
ランダムフォレストではN個の決定木の予測値の単純平均を取っています。
変数の定義
- y: ランダムフォレストの予測値
- x: 決定木の予測値
- N: 決定木の数
単純平均なので以下のような数式で計算することができます。
$$y = \frac{1}{N} \sum_{n=1}^{N}x_n $$どうしてランダムフォレストでは決定木を使うの?
アンサンブル学習のバギングは、複雑なモデル(分散大・バイアス小)を複数組み合わせて誤差を減らすという考え方をしています。
複雑なモデルはデータに柔軟にフィットできる一方で、過学習が起こりやすいというデメリットがあります。
過学習するとデータの外れ値による影響を受けやすいのですが、たくさんのモデルを使い平均を取ることでこのデメリットをなくせるのではないかと考えられています。。
決定木は複雑なモデルの代表例であり、バギングと相性が良いためランダムフォレストというモデルが生まれました。
また、決定木は「処理が高速」、「インプットのデータ型を問わない」、「スケーリングしやすい」といった特徴もあり、バギングに向いている機械学習モデルと言うことができます。
ランダムフォレストをpythonで実装
必要ライブラリのインポート
from sklearn.datasets import load_wine from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
データの生成
#データ生成 data = load_wine() X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3)
ランダムフォレストのモデルで学習する
#ランダムフォレストで分類する model = RandomForestClassifier() model.fit(X_train, y_train)#学習 y_pred = model.predict(X_test)#推定 accuracy_score(y_pred, y_test)
結果は
0.9814814814814815
となり、98%の分類精度となりました。
まとめ
ランダムフォレストとは何かをまとめると以下の3つの特徴を持つモデルです。
- 決定木を用いたアンサンブル学習(バギング)のモデル
- 分類と回帰問題のどちらにも用いることができるモデル
- シンプルなモデルが元になっているので、結果の透明性があるモデル


コメント