


















- ディープラーニング(Deep Learning)とは何か
- ディープラーニングは何をしているのか
- ディープラーニングのpython実装例
ディープラーニング(Deep Learning)とは?
ディープラーニング(Deep Learning)とは、
です。
ディープラーニングは分類と回帰のどちらの問題にも利用することもできます。
このアルゴリズムはニューラルネットワークを拡大させたモデルとです。
ディープラーニングのモデルは、よく下の図のように表されます。
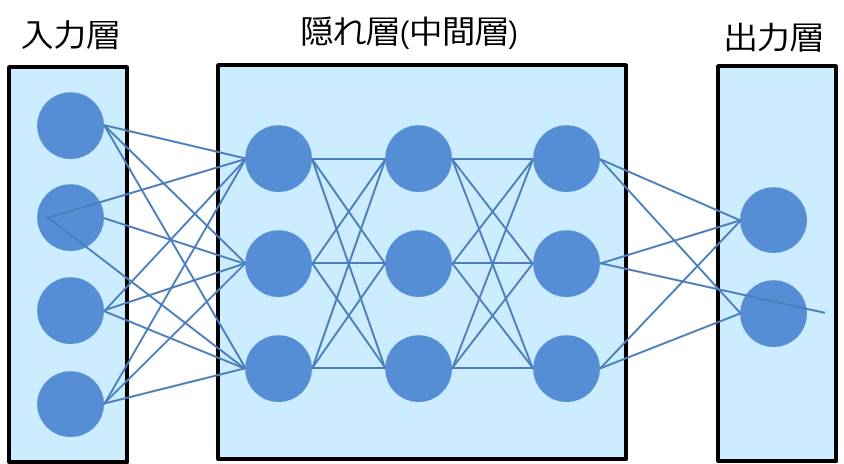
一番左の列が入力データ(入力層)であり、一番右の列が出力結果(出力層)となっています。
入力層と出力層の間の部分は隠れ層や中間層と呼ばれます。
ディープラーニングは何がすごいのか
ディープラーニングでは機械が知識を獲得できるということが、大きな特徴です。
猫の画像であるか判別する例を考えてみます。
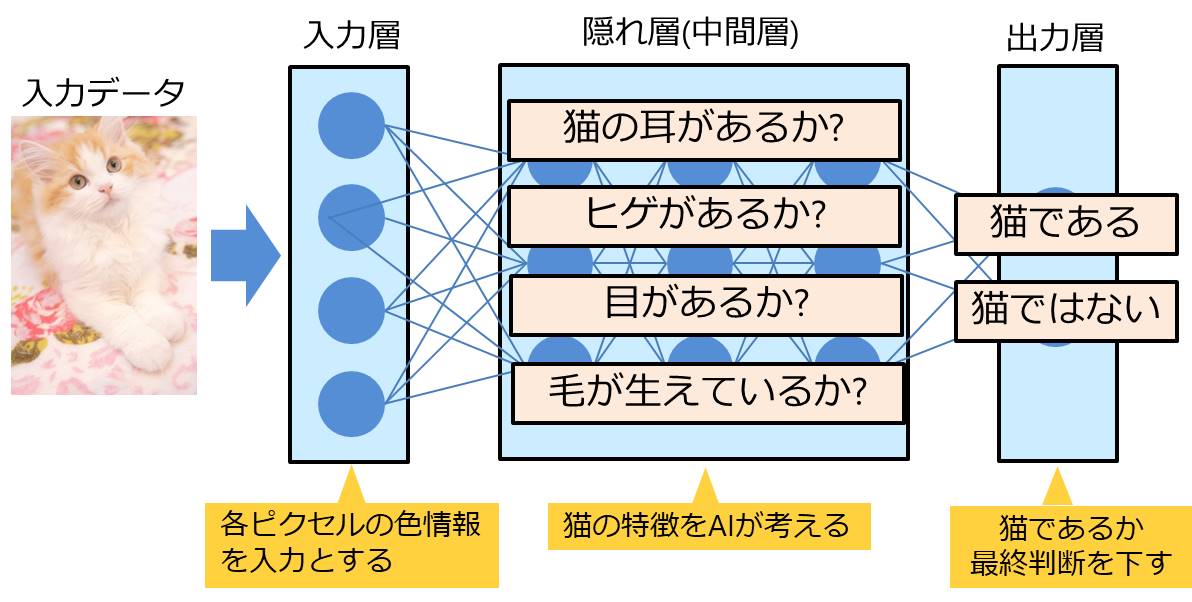
入力層が猫の画像の情報を表しています。
中間層では画像の特徴を判断し、出力層では結果を表しています。
中間層で判断している特徴はAIが自動的に抽出したもので、人間は定義していません。
この特徴を自動で抽出(知識を獲得)することが、近年ディープラーニングが注目されている理由の一つになっています。
今までの手法よりもディープラーニングはAIが考えてくれる範囲が増えたんだね。
ディープラーニング(Deep Learning)のアルゴリズム
ディープラーニングが何をやっているのか知るために、まずはモデル図が何を表しているのか説明していきます。
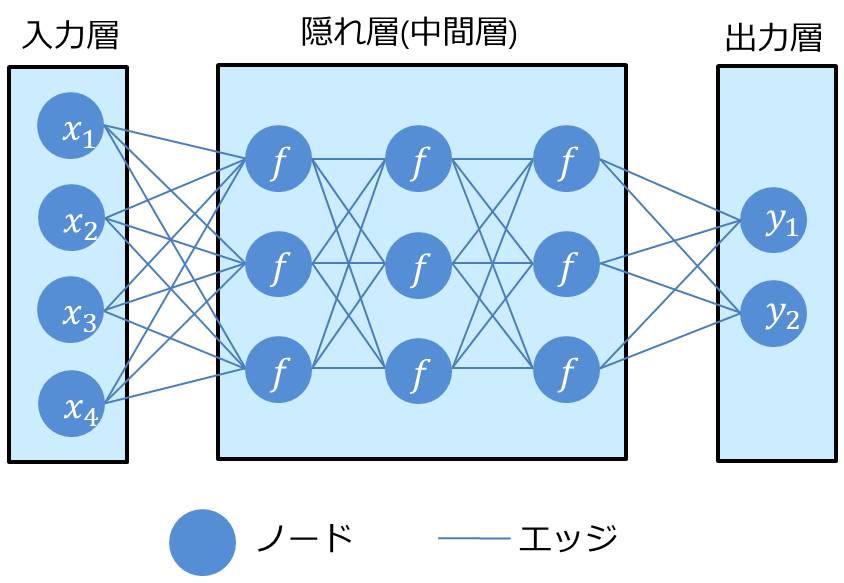
ディープラーニングのモデル図では、「ノード」が「エッジ」で結ばれる構造となっています。
ノードは関数を表していて、エッジはノードへの入力を表しています。
隠れ層の最初のノードの1つを例として見ていきましょう。
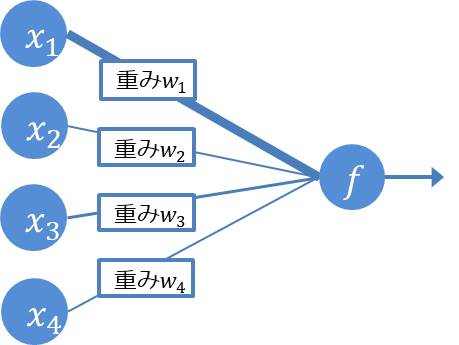
このノード(関数f)には、エッジがつながっている $$ x_1 , x_2 , x_3 , x_4 $$が入力されていることが分かります。
入力値はそのままノード(関数f)に伝えられるわけではなく、エッジごとに重み(結合の太さ)にパラメータwが設定されます。
この重みwをうまく調整する(機械が考えてくれる)ことで特徴量を作り出しています。
つまり、隠れ層の最初のノードの出力は以下の式で表すことができます。
$$f(w_1 x_1 + w_2 x_2 + w_3 x_3 + w_4 x_4) $$
この3層のディープラーニングのモデルでは、入力層のデータxを関数fの入力とした結果をまた関数fの入力にするということを3回繰り返して出力層の結果yを出力していることを表しています。
ディープラーニングはノード(関数)をいくつも重ねたモデルなんだね。
ノードの関数ではどんなことをしているの?
次にノードの関数fでは何をしているのか説明していきます。
ディープラーニングの関数fには、活性化関数が使われます。
活性化関数では次のノードにどのくらいの情報を伝える役割をしています。
活性化関数にはReLU(Rectified Linear Unit)関数が使われることが一般的です。
ReLU関数は0より小さい入力は0とし、0より大きい入力はそのまま帰す関数です。
f(x)=max(0,x)= \begin{cases}
x & (0 \le x) \\
-x & (x < 0)
\end{cases}
$$
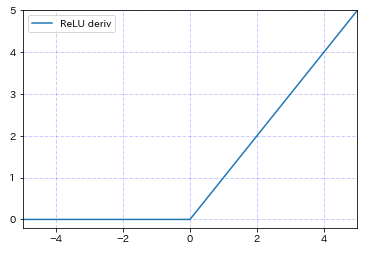
ReLU以外の活性化関数が知りたい場合は、この記事でまとめているので読んでみて下さい。

ディープラーニングの学習を視覚的に見てみる
説明を読無駄毛ではイメージがつかめなかった人は実際に試して視覚的に理解してみましょう。
「TensorFlow Playground」というサイトでディープラーニングの仕組みを試すコンテンツが用意されています。
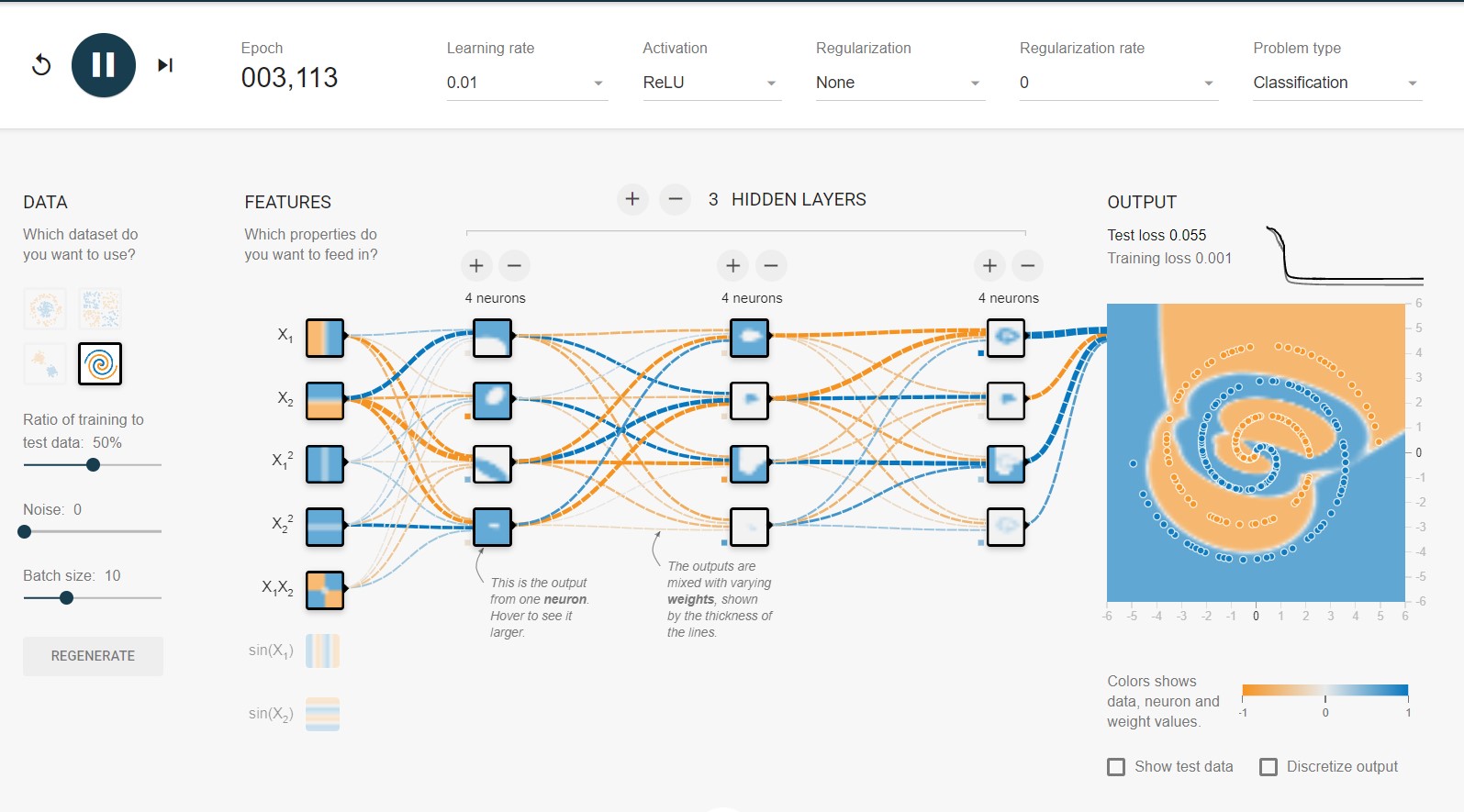
こんな感じで、渦巻き型データの分類問題もある程度の精度であれば簡単にできてしまいます。
入力を変えたり層の数を増減もできるので皆さんも試してみて下さい。

ディープラーニング(Deep Learning)をpythonで実装
ディープラーニングの計算例をpythonで実装してみました。
今機械学習のライブラリであるsklearnを使いソフトマージンで分類を行います。
検証データは機械学習のチュートリアルによく使われるMNISTのデータセットを使いました。
必要ライブラリのインポート
from sklearn.datasets import load_digits from sklearn.neural_network import MLPClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
データの生成
#データの読み込み data = load_digits() X = data.images.reshape(len(data.images), -1) y = data.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
ディープラーニングのモデルで学習する
#サポートベクターマシンで分類する model = MLPclassifier(hidden_layer_sizes=(100,100,100)) model.fit(X_train, y_train)#学習 y_pred = model.predict(X_test)#推定 accuracy_score(y_pred, y_test)#正解率
ディープラーニングではデータさえ用意すればある程度の精度までは簡単に出すことができるよ。
技術が進歩すればもっと簡単に何でもできるようになるかもしれないね。
まとめ
今回はディープラーニング(Deep Learning)とは何かを説明しました。
ディープラーニング(Deep Learning)は、人の神経を模倣したモデルで、分類と回帰のどちらの問題にも利用できるモデルでしたね。
ディープラーニング(Deep Learning)は、活性化関数に何度も繰り返し入力し特徴量を機械が考えていくというモデルです。
最近のAIブームの火付け役とも言える画期的なモデルなので、今後もどんどん進化していきできることが増えていくでしょう。

コメント