


















- GBDT(勾配ブースティング木)とは何か
- GBDTの特徴
- GBDTのライブラリ
GBDTの正式名称は「Gradient Boosting Decision Tree」で、使っている手法を羅列した名前となっています。
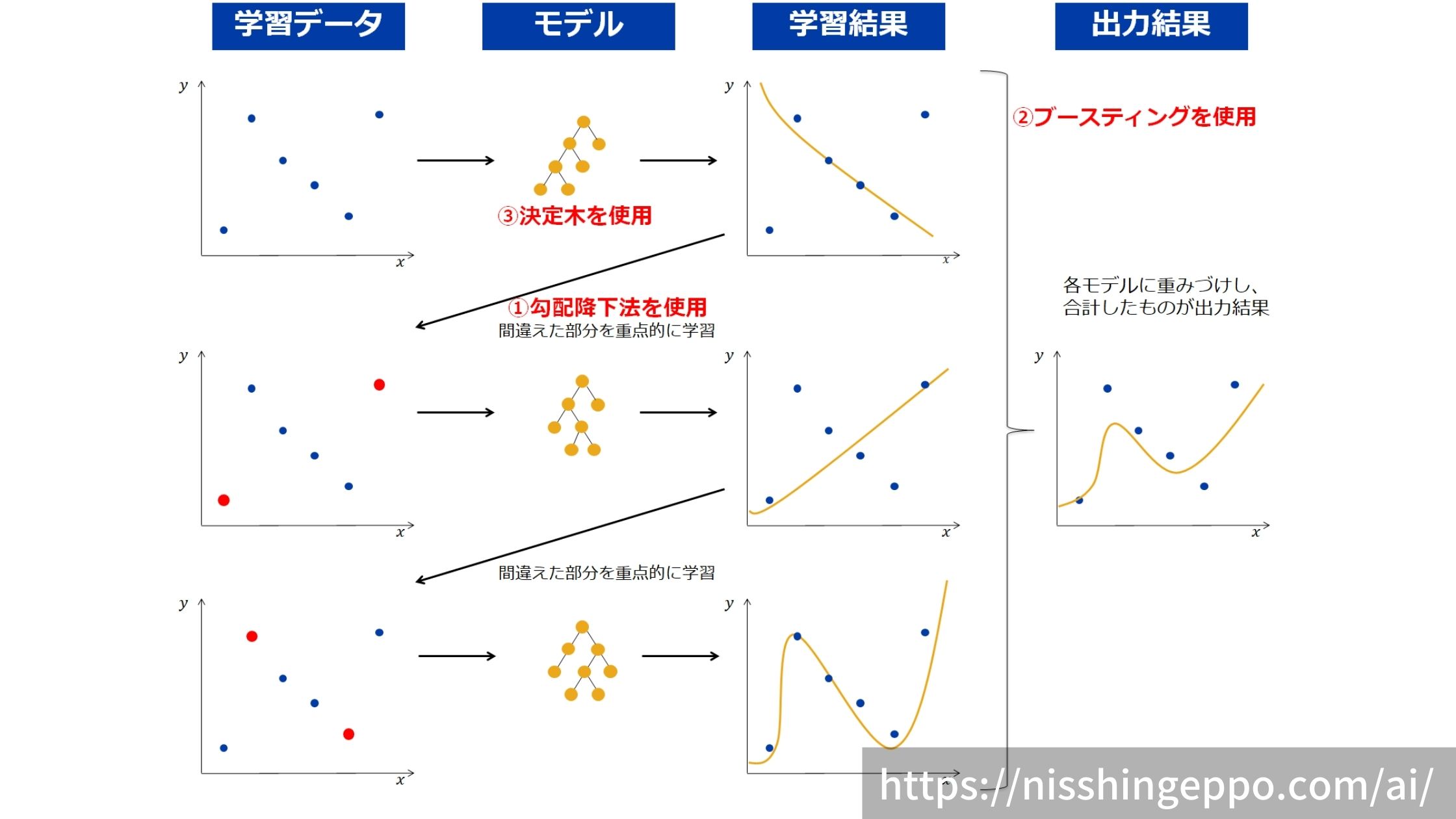
GBDTでは、機械学習のアルゴリズムに決定木を使用しています。
そして、決定木だけでは精度があまり出ないため、アンサンブル学習のブースティングを使用しています。
ブースティングの際に、前の予測値の誤差を最小化するために勾配降下法を使います。
続いて、GBDTで使われている3つの手法について簡単に解説していきます。
決定木(Decision Tree)
決定木とは、
です。
例えば運動会の中止の判断を決定木で表すことができます。
「雨が降っていたら中止」、「風が強かったら中止」といった条件を使って結果を判断しています。
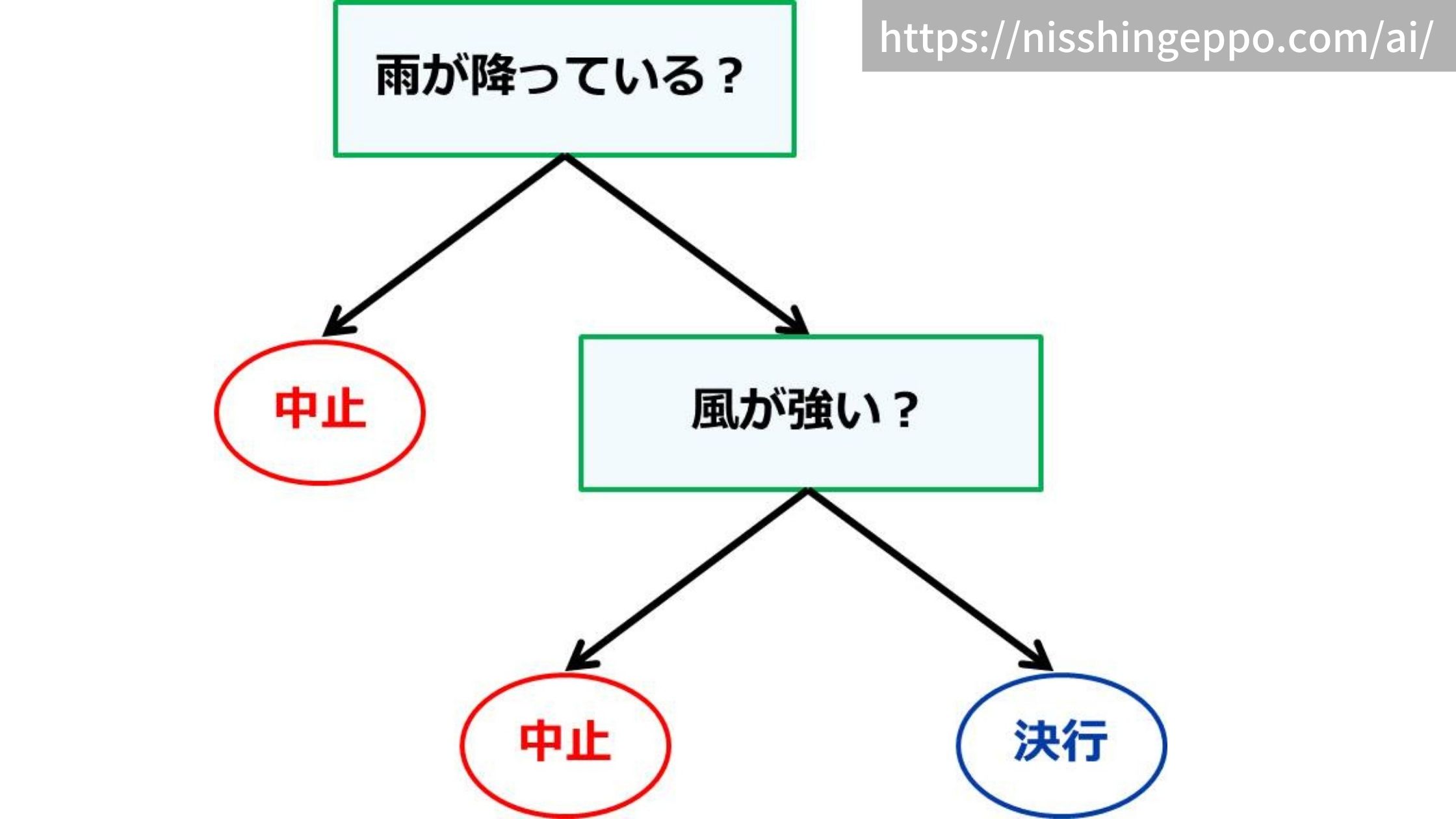
直感的でわかりやすい手法なので、日常生活でも無意識に使っているかもしれませんね。
決定木について詳しく知りたい方はこちらの記事を参考にしてください。

ブースティング(Boosting)
ブースティングとは、
です。

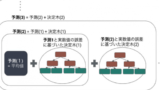
ブースティングでは、前の学習モデルが間違えた部分を補うようにモデルを作っていきます。
まず1つ目のモデルは学習データを通常通り学習していきます。
次に、2つ目のモデルは1つ目のモデルが間違ったデータを重要視して学習していきます。
3つ目のモデルは今までのモデル(1つ目と2つ目)が間違ったデータを重要視して学習するといったように、連続的に学習していくことで、より精度を向上させていくことができる手法です。
アンサンブル学習について詳しく知りたい方はこちらの記事を参考にしてください。

勾配降下法(Gradient)
勾配降下法とは、
です。
下の図のように、今いる点のグラフの傾きを見て、下っている方向を探索する手法になります。
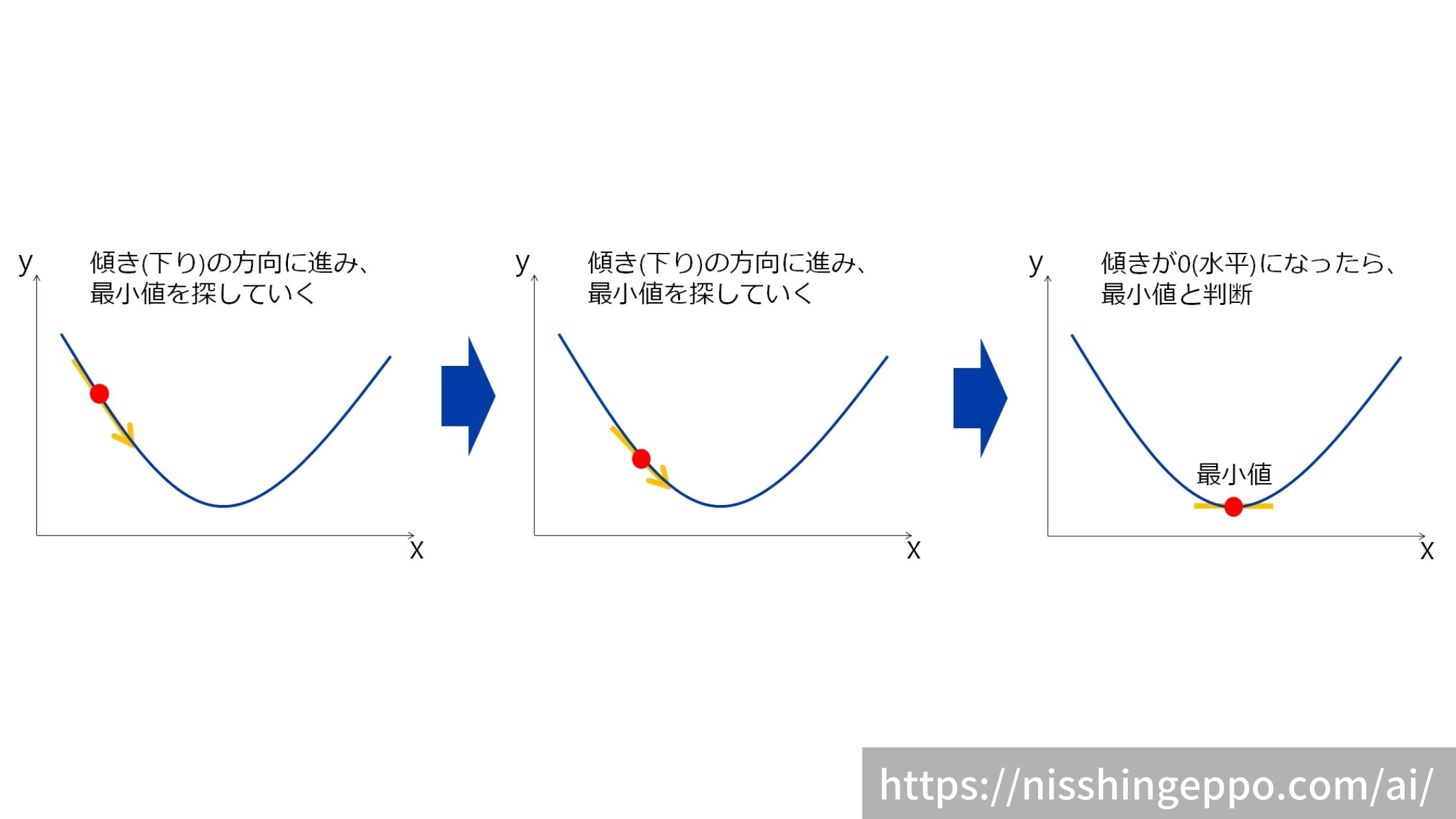
グラフを見ればどこが最小値かなんてひと目で分かると思ってしまいますが、データの量が多いと全体を把握できません。
一部のデータだけで最小値を見つけるように考えられた方法となります。
勾配降下法について詳しく知りたい方はこちらの記事を参考にしてください。

GBDT(勾配ブースティング木)の特徴
GBDTは精度が高く、使いやすいという理由で、データ分析コンペでもよく使われる手法です。
GBDT(勾配ブースティング木)のメリット
- 精度が高い
- 使いやすい
精度が高い
精度が高くなりやすい理由の一つは、ハイパーパラメータのチューニング等の職人芸がなくてもある程度の精度を出せることです。
また、分岐を繰り返すことで、変数間の相互作用がうまく処理されることも要因の一つとなっています。
使いやすい
GBDTの使いやすさは、データの前処理の手間が少ないことが挙げられます。
決定木では特徴量の大小関係で分岐を作るため、データの前処理(標準化など)をせずに利用することができます。
また、数値の比較を行うのでカテゴリ変数をそのまま使えるので要素数も増えず便利です。
GBDT(勾配ブースティング木)のデメリット
- 特徴量は数値にする必要がある
- 過学習が起こりやすい
- 学習に時間がかかる
メリットでもありましたが、決定木では数値の比較を行うため文字列のデータは数値に変換しないと正しく学習することができません。
また、ブースティングで同じデータを何度も利用しているので、過学習が起こりやすくなります。
ブースティングでは複数のモデルを直列にして学習を進めるため、時間もかかってしまいます。
GBDT(勾配ブースティング木)のライブラリ
GBDTの代表的なライブラリは以下があります。
これらのライブラリは同じGBDTの手法を使っているのですが、学習アルゴリズムなどが若干異なります。
xgboost
xgboostは2014年に公開され、精度と使いやすさから分析コンペでよく使われてきました。
このライブラリは長く使われており、資料も豊富にそろっています。
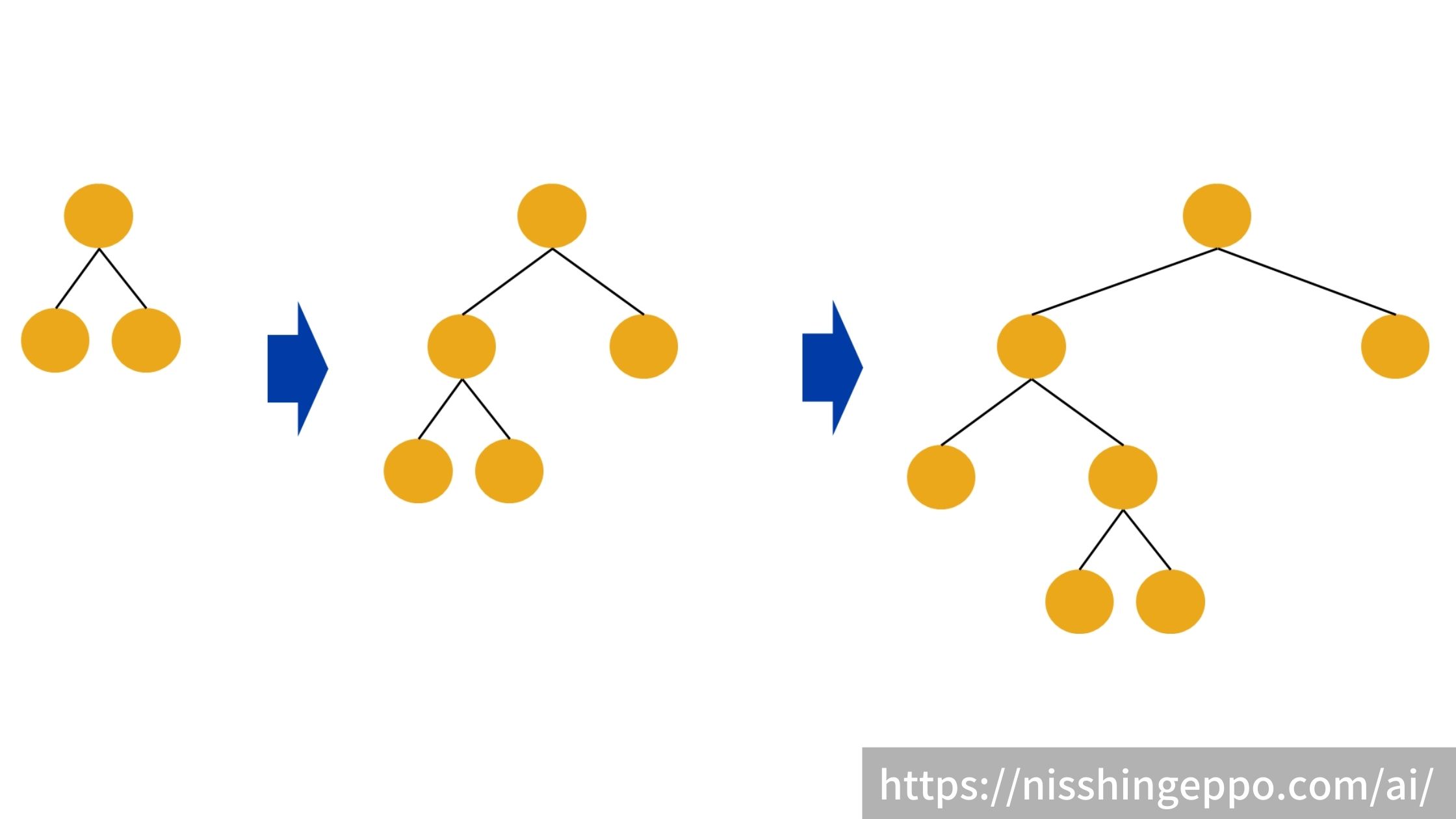
xgboostの特徴としては、決定木の学習を深さ単位で行っています。

lightgbm
lightgbmは2016年に公開され、高速であることから近年よく使われるようになってきています。
lightgbmの特徴としては、決定木の学習を分岐させるべき葉に絞って実施しています。
catboost
catboostは2017年に公開されたカテゴリ変数の扱いなどに特徴的な工夫をしたGBDTのライブラリです。
catboostの特徴は、カテゴリ変数として指定した特徴量を自動的にtarget encordingを行い、数値に変換します。
また、決定木の分岐の条件式を最適化して、過学習を防いでいます。
まとめ
GBDT(勾配ブースティング木)とは、「勾配降下法(Gradient)」と「ブースティング(Boosting)」、「決定木(Decision Tree)」の3つの手法が組み合わされた機械学習の手法です。
メリットは、精度が高い 、使いやすいということが挙げられます。
GBDTのライブラリには、xgboost、lightgbm、catboostがあります。
データ分析コンペでもよく使われる優秀な手法なので、ぜひ使ってみてください。
参考文献




コメント
[…] 先人の記事だと、これがマジでわかりやすい。 […]
[…] https://nisshingeppo.com/ai/whats-gbdt/ […]