


















- k-means法とは何か
- k-means法のアルゴリズム
- k-means法の評価方法
k-means法とは
k-means法とは、
です。
k-means法はシンプルな手法で、比較的大きなデータへの適用も可能なため幅広い分野で利用されている手法です。
ただし、k-means法は初期値によって結果が変わってしまうので複数回繰り返して使ったり、初期値の選び方を工夫することがあります。
k-means法のアルゴリズム
k-means法は以下のような手順で実施します。
- ステップ1クラスタの数を決める
- ステップ2クラスタの数だけ適当な点(重心の初期値)を設定する
- ステップ3重心を元にデータをクラスタリングする
- ステップ4各クラスの重心を再計算する
- ステップ5ステップ3とステップ4を変化がなくなるまで繰り返す
例としてこちらのデータセットを分類してみます。
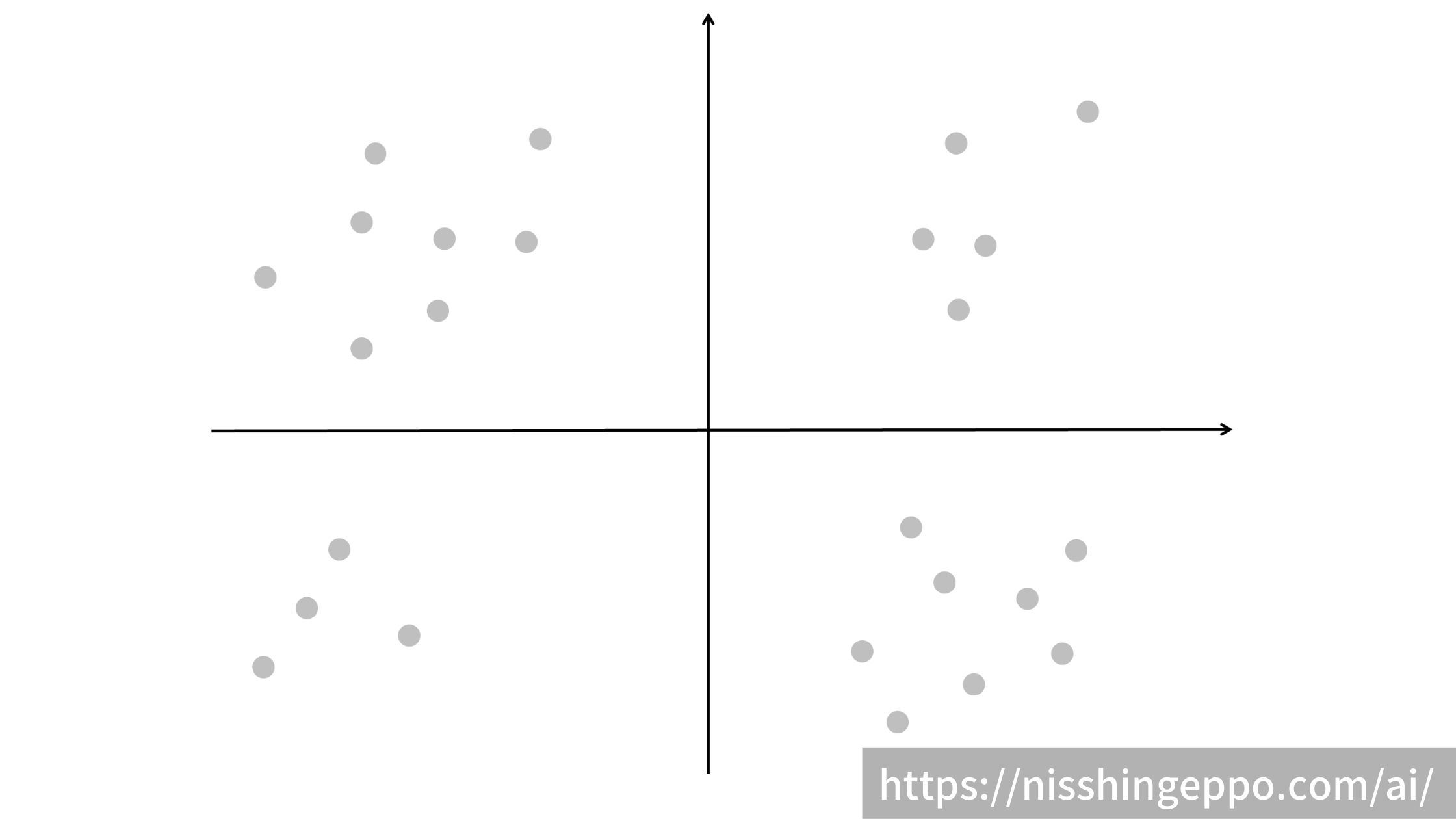
ステップ1:クラスタの数を決める
データセットをいくつに分類したいかクラスタ数を決めます。
今回はクラスタ数を4として進めていきます。
ステップ2:クラスタの数だけ適当な点(重心の初期値)を設定する
ステップ1で設定したクラスタ数に従い、ランダムに重心の初期値を設定します。
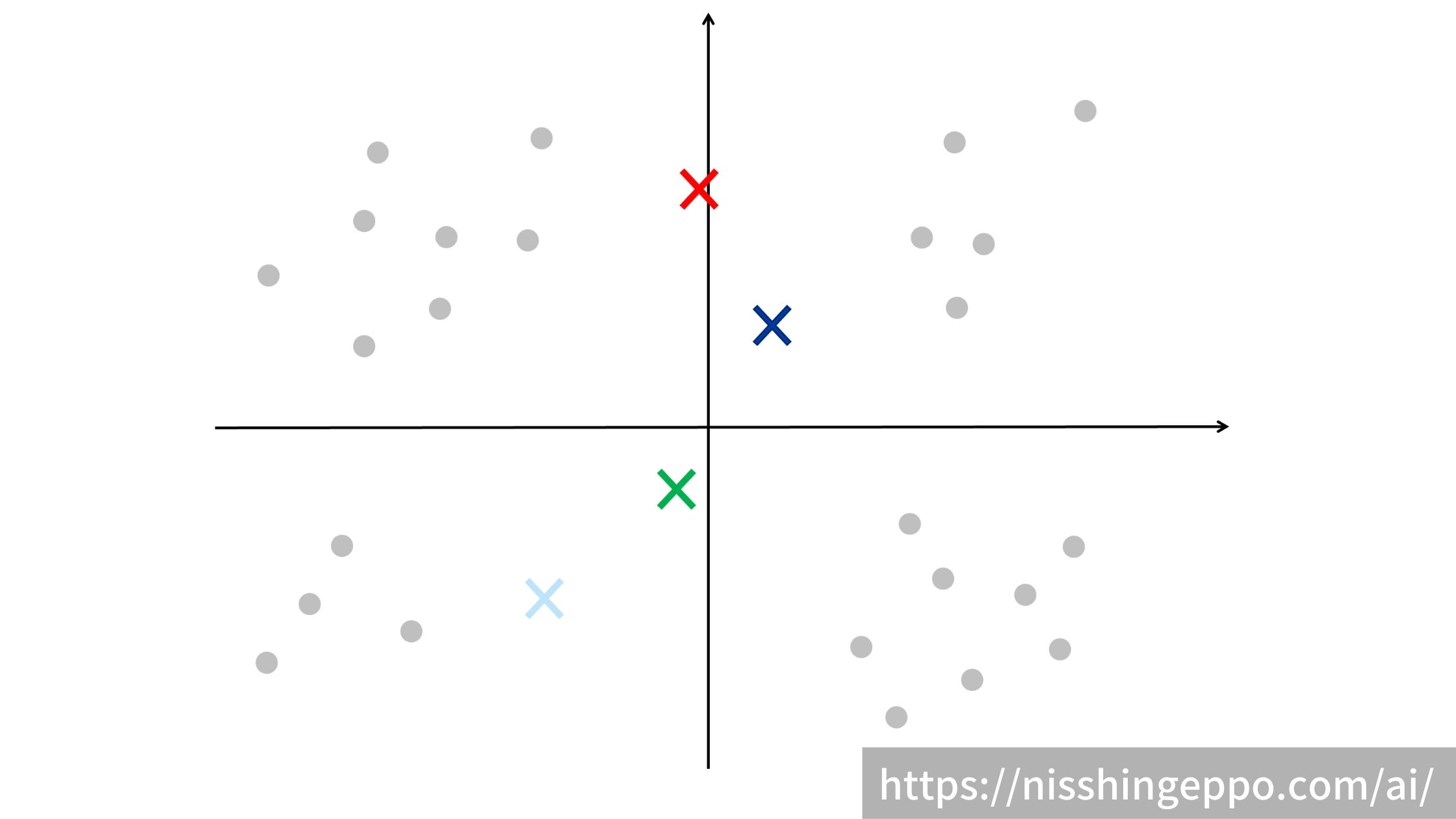
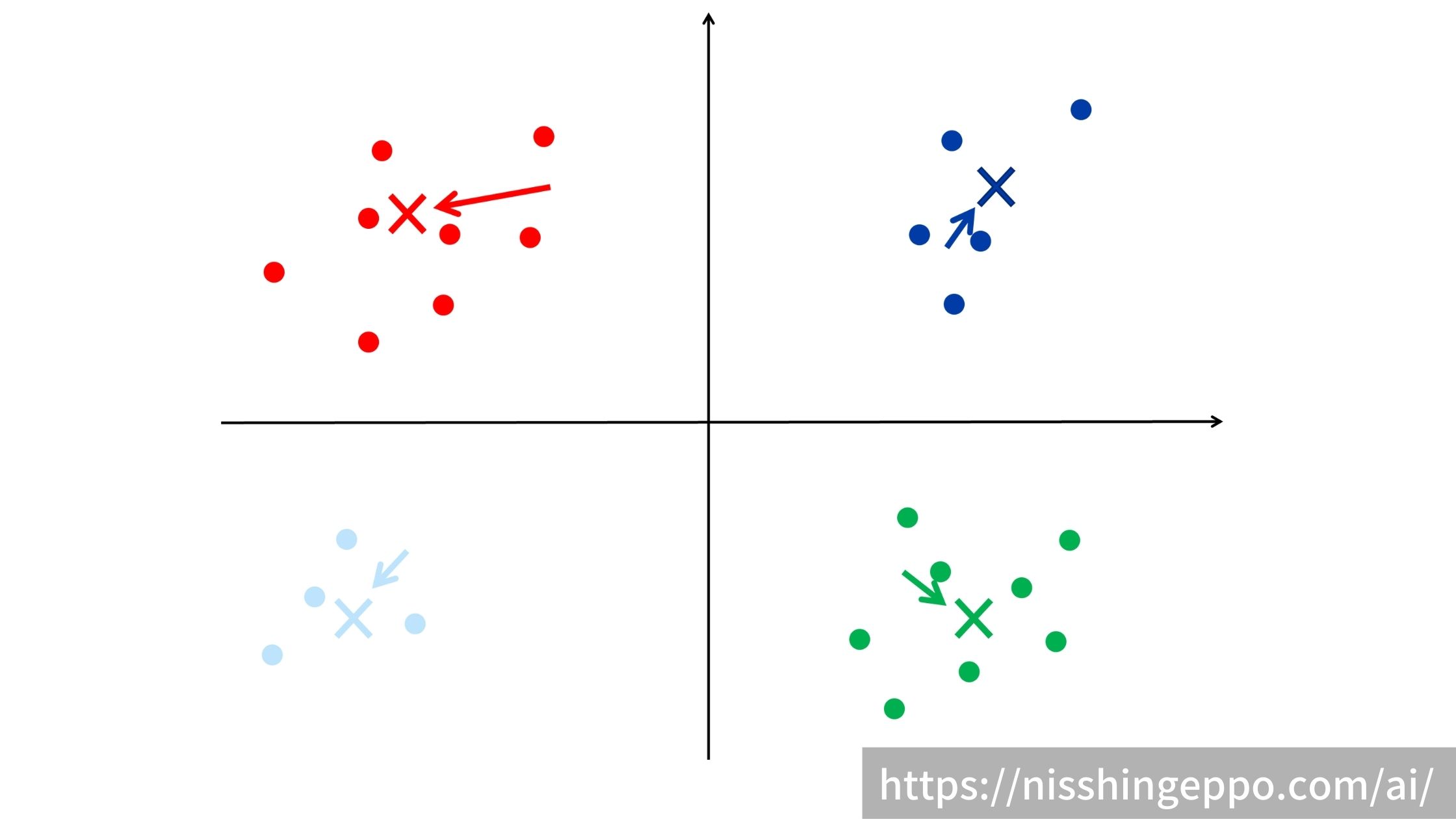
ステップ3:重心を元にデータをクラスタリングする
重心からの距離に応じてデータをクラスタリングします。
データは一番近い重心のクラスタに所属します。
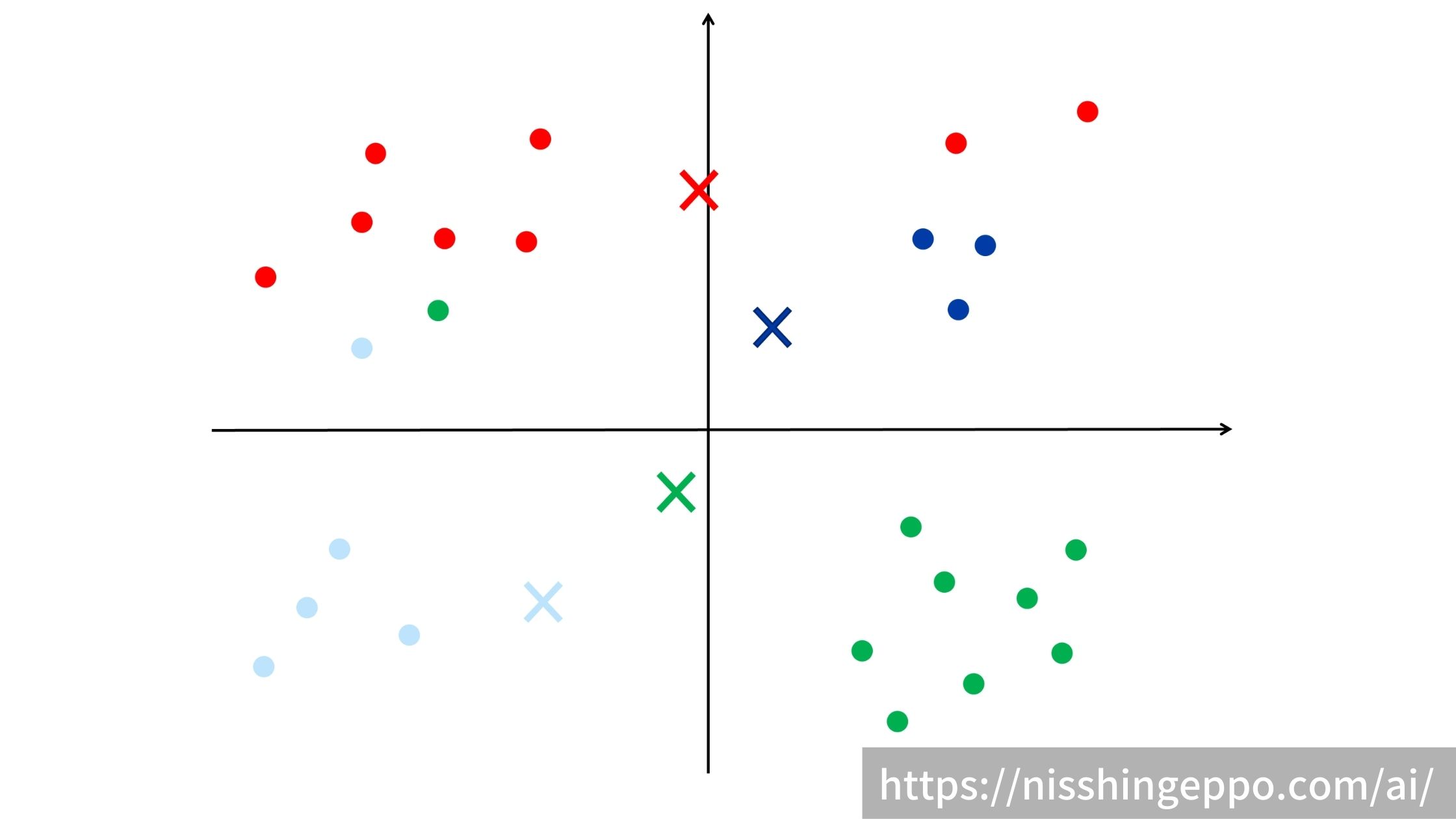
ステップ4:各クラスの重心を再計算する
ステップ3でクラスタリングされたデータを元に各クラスの重心を求めます。
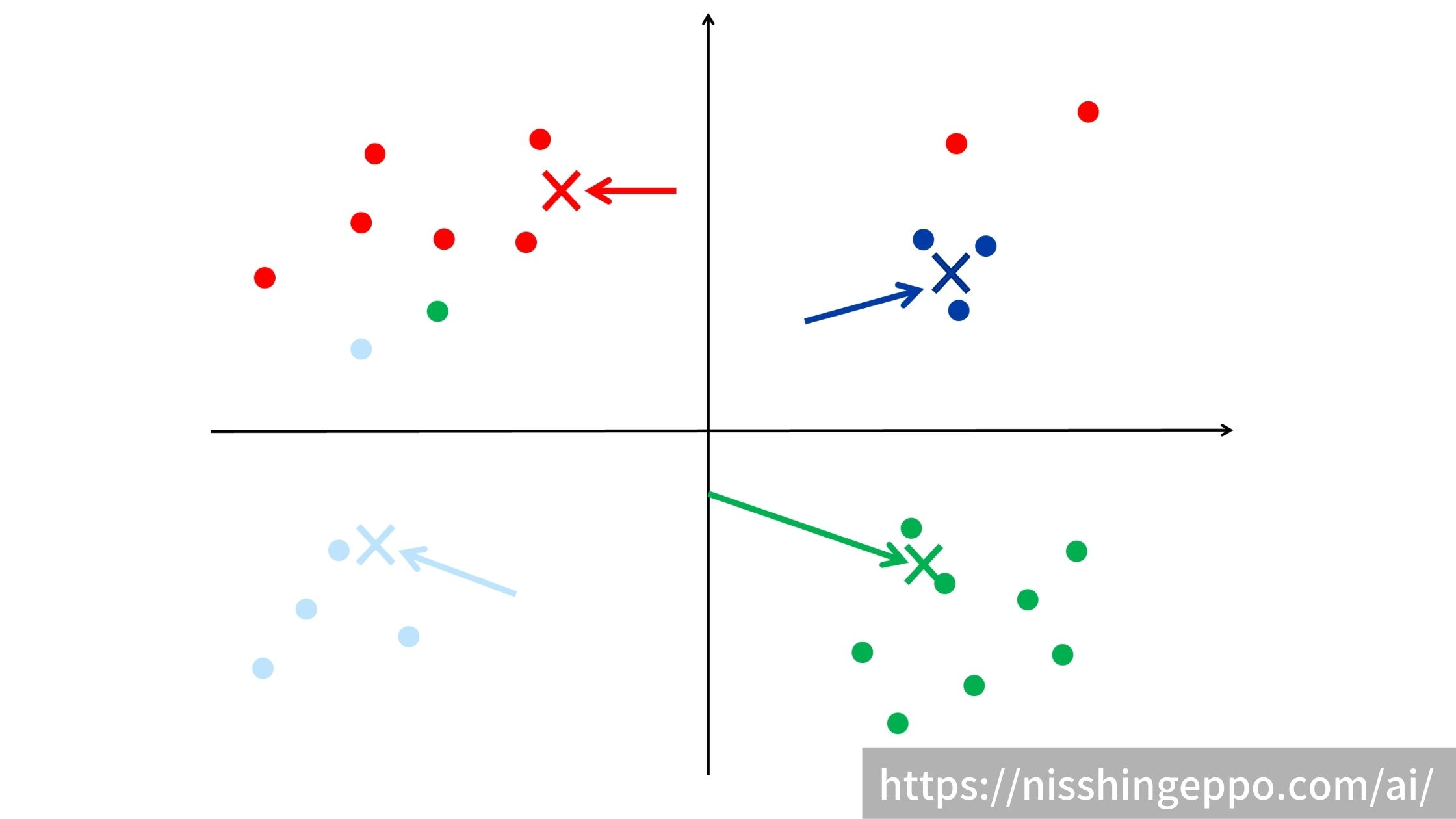
ステップ5:ステップ3とステップ4を変化がなくなるまで繰り返す
ステップ3とステップ4を繰り返して、変化がなくなった時点の状態がk-means法の出力となります。
k-means法の評価方法
k-means法でクラスタリングした結果は、クラスタ内平方和(Within-Claster Sum of Square)で定量的に評価することができます。
クラスタ内平方和(WCSS)はクラスタの重心とクラスタ内のデータの距離の合計で表されます。
\(J=\sum ^{k}_{j=1}\sum ^{n}_{i=1}\left\| x_i^{(j)}-c_{j}\right\| ^{2}\)
- J:クラスタ内平方和(WCSS)
- x:データの位置
- c:重心の位置
クラスタ内平方和(WCSS)が小さいほどk-means法の結果が良くなっていると判断します。
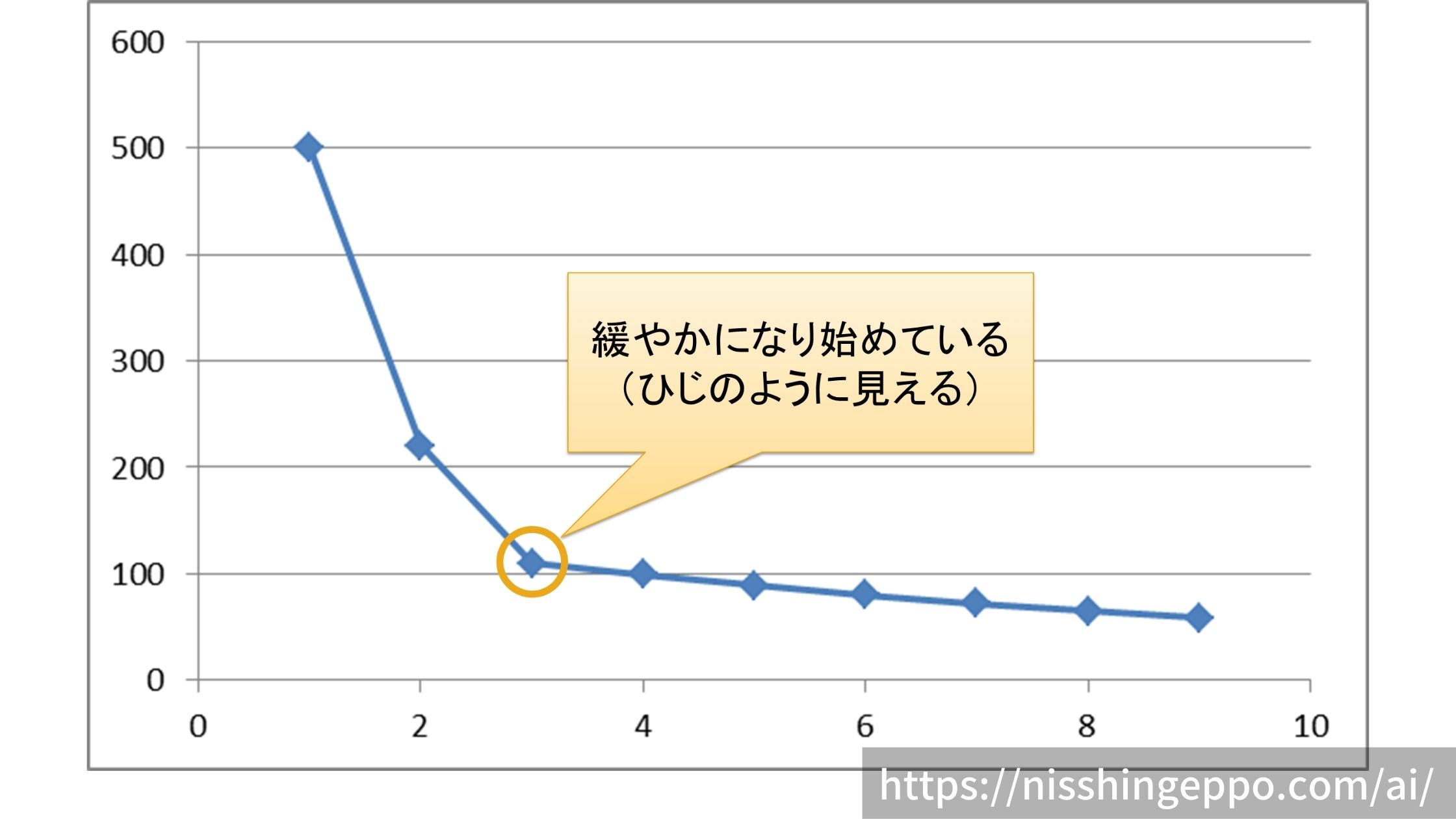
クラスタ内平方和(WCSS)をクラスタ数を決める指標に使う
k-means法のクラスタ数はハイパーパラメータなので学習の際に設定する必要がありますが、データセットによっては決めることが難しい場合があります。
その時にクラスタ内平方和(WCSS)を目安にクラスタ数を決めることができます。
代表的な手法として「WCSSが緩やかになり始めていて、ひじのように見える部分をクラスタ数として選択する」というElbow法などが挙げられます。
まとめ
k-means法とは、クラスタリング手法の1つで、データの重心を求めることで分類するアルゴリズムです。
k-means法はシンプルな手法で、比較的大きなデータへの適用も可能なため幅広い分野で利用されている手法です。
ただし、k-means法は初期値によって結果が変わってしまうので複数回繰り返して使ったり、初期値の選び方を工夫することがあります。



コメント