


















- 機械学習手法の選択の観点
- 機械学習手法の実践的選択方法
機械学習の手法には様々なものがありますが、初学習者にはどの手法を使えばよいか分からないと思います。
状況に応じて臨機応変に選ぶというのが正しいのですが、それだと元も子もないのである程度の指針をまとめました。
モデル選択の観点
機械学習モデルは以下の観点で選択していきます。
- 精度
- 計算速度
- 使いやすさ
- 多様性
精度
これが重要なことは自明ですね。
精度の高い予測を行うことがデータ分析の目的なので、機械学習モデルの選択で最優先するポイントです。
計算速度
機械学習では様々なパラメータや特徴量を変えて試行錯誤をするため、計算速度も重要なポイントです。
1回のモデル作成に時間がかかりすぎるとチューニングが難しいため、採用しづらいモデルとなります。
使いやすさ
特徴量の作成や欠損値の修正などの前処理が単純になると、リークさせてしまうなどの人為的ミスも減ります。
また、判定基準が人間にも分かりやすいことも重要です。
モデルの出力がどうしてそうなったのか説明できると、人間の直感と合っているかなどの観点で評価することでおかしなモデルに気づくことができます。
多様性
アンサンブル学習をする前提の話となりますが、他のモデルと違う観点で判断するモデルは有用となります。
たとえ単体のモデルの精度が悪かったとしても、アンサンブルでの精度向上には寄与できるからです。
例えば、晴れの日の予測精度は悪いが、雨の日の予測精度が高いようなモデルならば、雨の日の予測部分でアンサンブルに貢献できるということですね。
チートシート
機械学習手法を選択するための指針もすでにいくつか存在しているので紹介していきます。
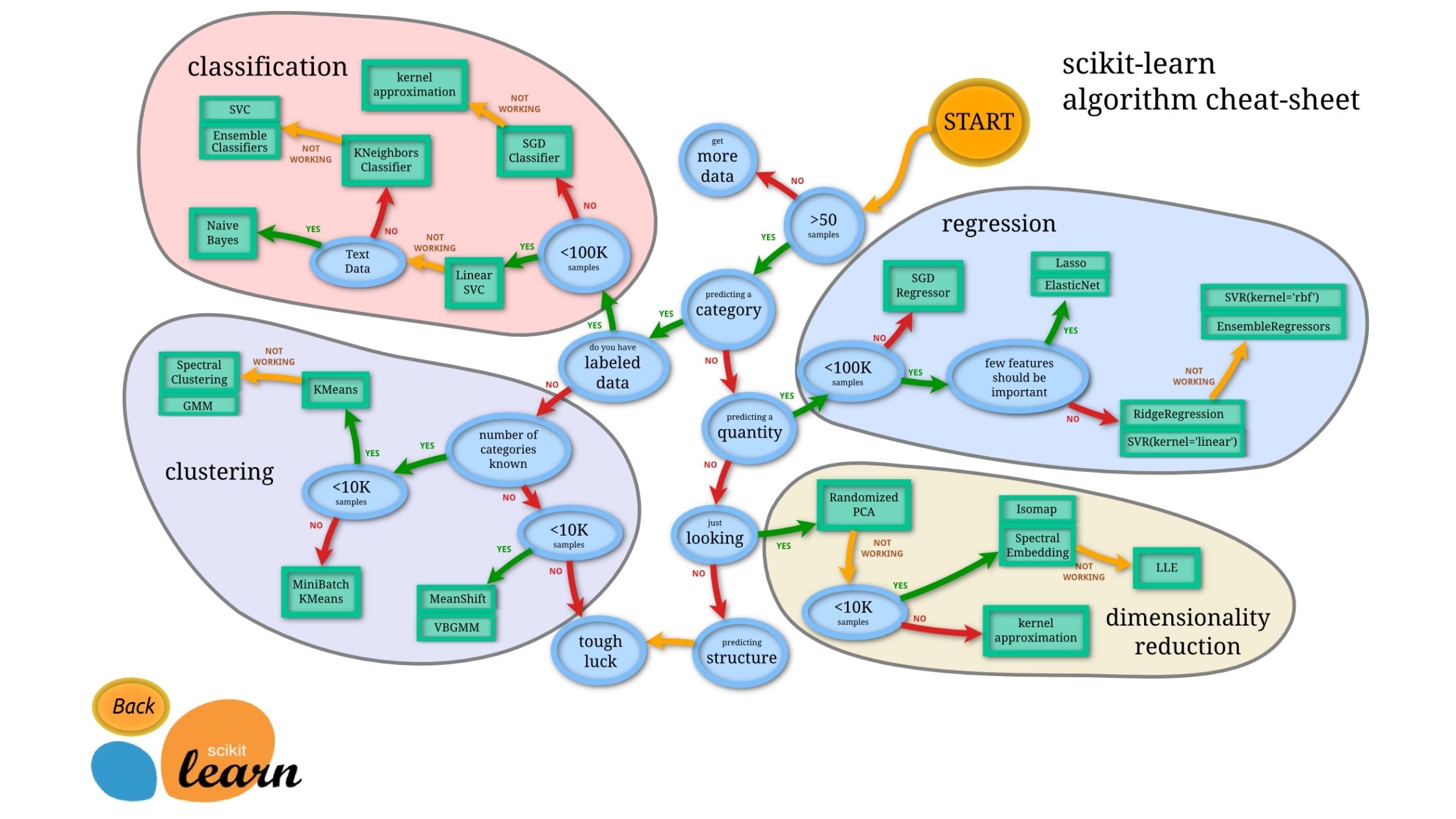
scikit-learn
Azure
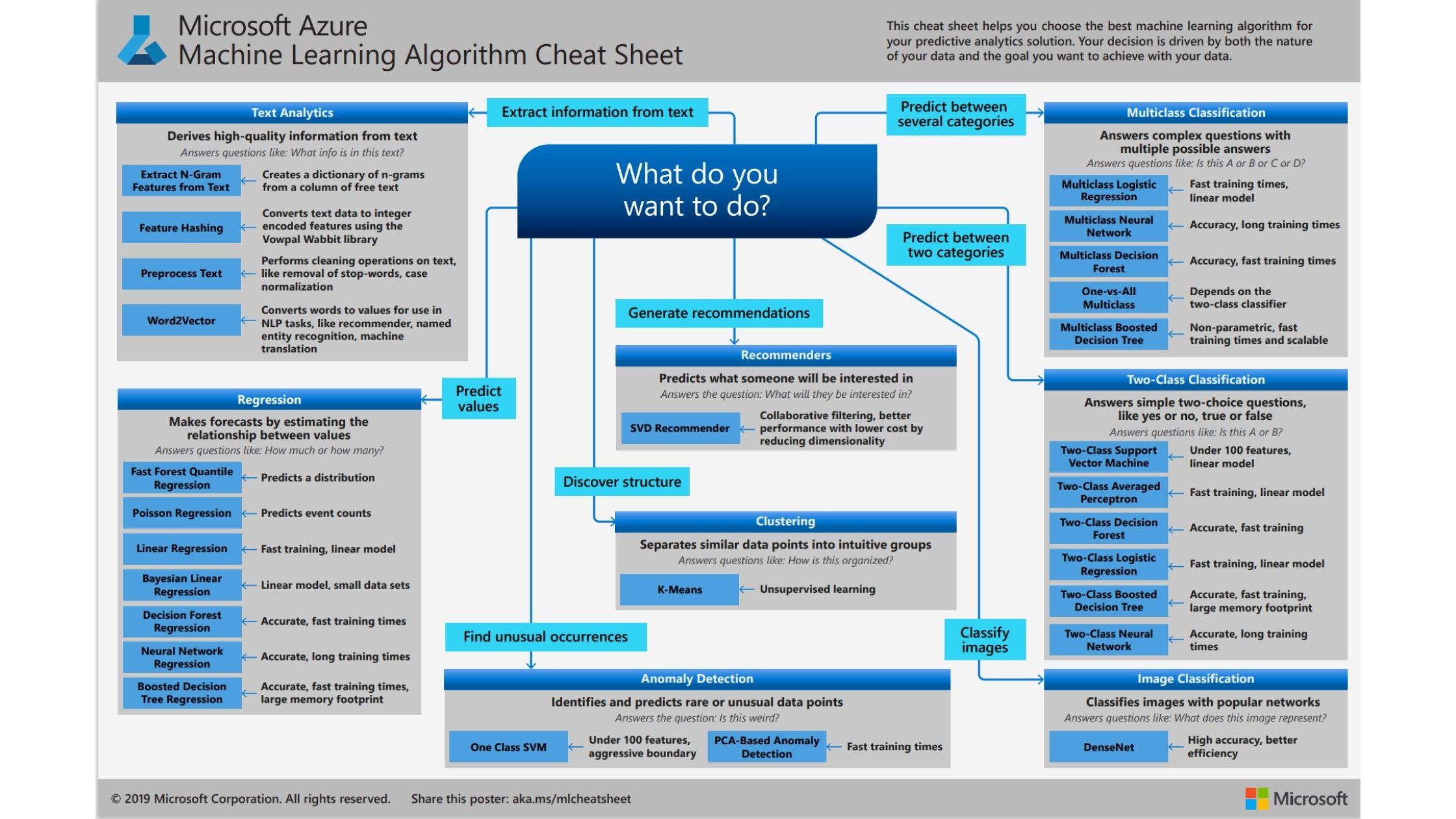
出典元:microsoft公式サイト
Sas
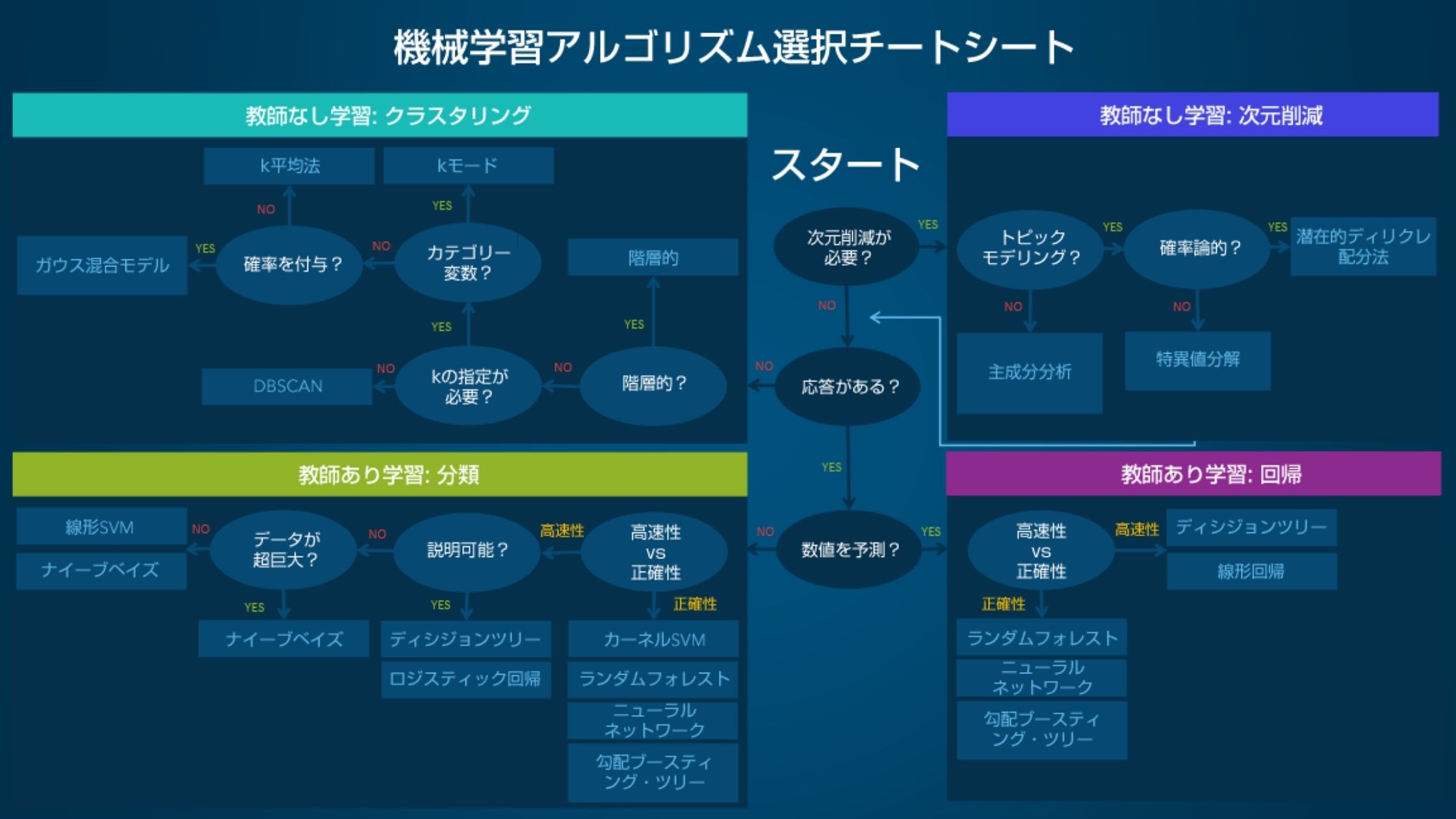
出典元:sas公式サイト
共通して以下のことが読み取れました。
- 正確なモデルを作る場合は、ランダムフォレストやニューラルネットワーク、勾配ブースティング木を使用する
- 高速なモデルには線形モデルを使用する
より実践的な機械学習手法の選択方法
実際の解析を行うときには何をすればよいのか、より具体的にまとめました。
今回はテーブルデータの分析をする場合の機械学習手法の選択方法を紹介します。
- ステップ1GBDT
- ステップ2ニューラルネット
- ステップ3線形モデル10万以上の大量のデータがあったり、過学習しやすい場合
- ステップ4アンサンブル学習k近傍法、ランダムフォレスト、RGF、FFMなど
とりあえず、GBDTとニューラルネットを使ってみるのが良いかと思います。
2021年現在では、GBDTもしくはニューラルネットのどちらかが比較的精度の出しやすい手法となっています。
100万以上の大量のデータがあったり、過学習しやすくGBDTやニューラルネットで精度が出ないときには、線形モデルも有効な手法となってきます。
それでも精度が足りない場合には、他のモデルを使いアンサンブル学習をしていくのが一般的です。
機械学習の代表的な手法の1つであるサポートベクターマシン(SVM)は、精度や計算速度の問題で実用されることが少なくなっています。
まとめ
機械学習の手法の選択方法を解説していきました。
選択の観点には4つあり、精度・計算速度・使いやすさ・多様性を意識する必要があります。
データ解析をする際には、GBDTとニューラルネットのモデルをまずは作成し、他のモデルも追加してアンサンブル学習をしていけばそれなりの結果を得られると思います。
もっと高い精度を出すためには、課題に応じたモデルの選択が必要になります。



コメント