

















- LSTMを用いて価格推定を実装
AI(機械学習)を使った株価分析を勉強しながら実践していく、実験ノートのような記事となります。
データ分析の経験は全くなく手探りで進めていくので、温かい目で見ていただきたいです。
コメントやアドバイスなどいただけると非常に助かります。
概要
株価データをLSTMを使って予測してみました。
用意したデータはソフトバンクの株価データ20年分(5389日分)です。
過去50日の株価データを入力し、翌日の株価を予測するということをやってみました。
やったこと
まずは初期設定
ライブラリのインポート
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn import preprocessing
import tensorflow as tf
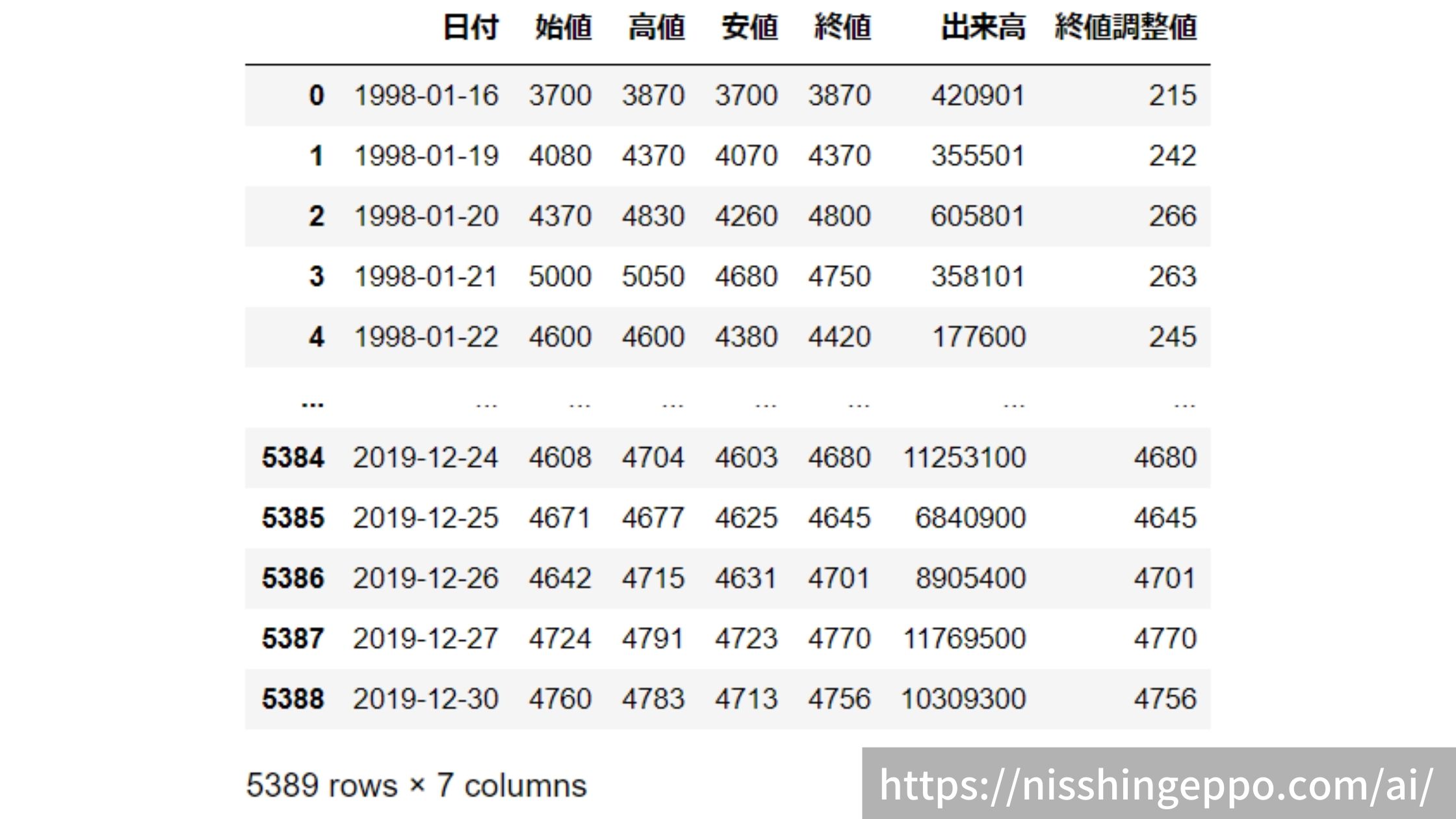
データの確認
データを読み込みます。
# データセット保存先ディレクトリ
data_dir="/path/to"
# 読み込むファイルを定義します。
data_file = f"{data_dir}/9984.csv"
# ファイルを読み込みます
dfs = pd.read_csv(data_file, header=None)
dfs.columns =["日付","始値","高値","安値","終値","出来高","終値調整値"]
# カラムの型を修正
dfs[["始値","高値","安値","終値","出来高","終値調整値"]] = dfs[["始値","高値","安値","終値","出来高","終値調整値"]].astype(int)
dfs["日付"] = pd.to_datetime(dfs["日付"])
dfs
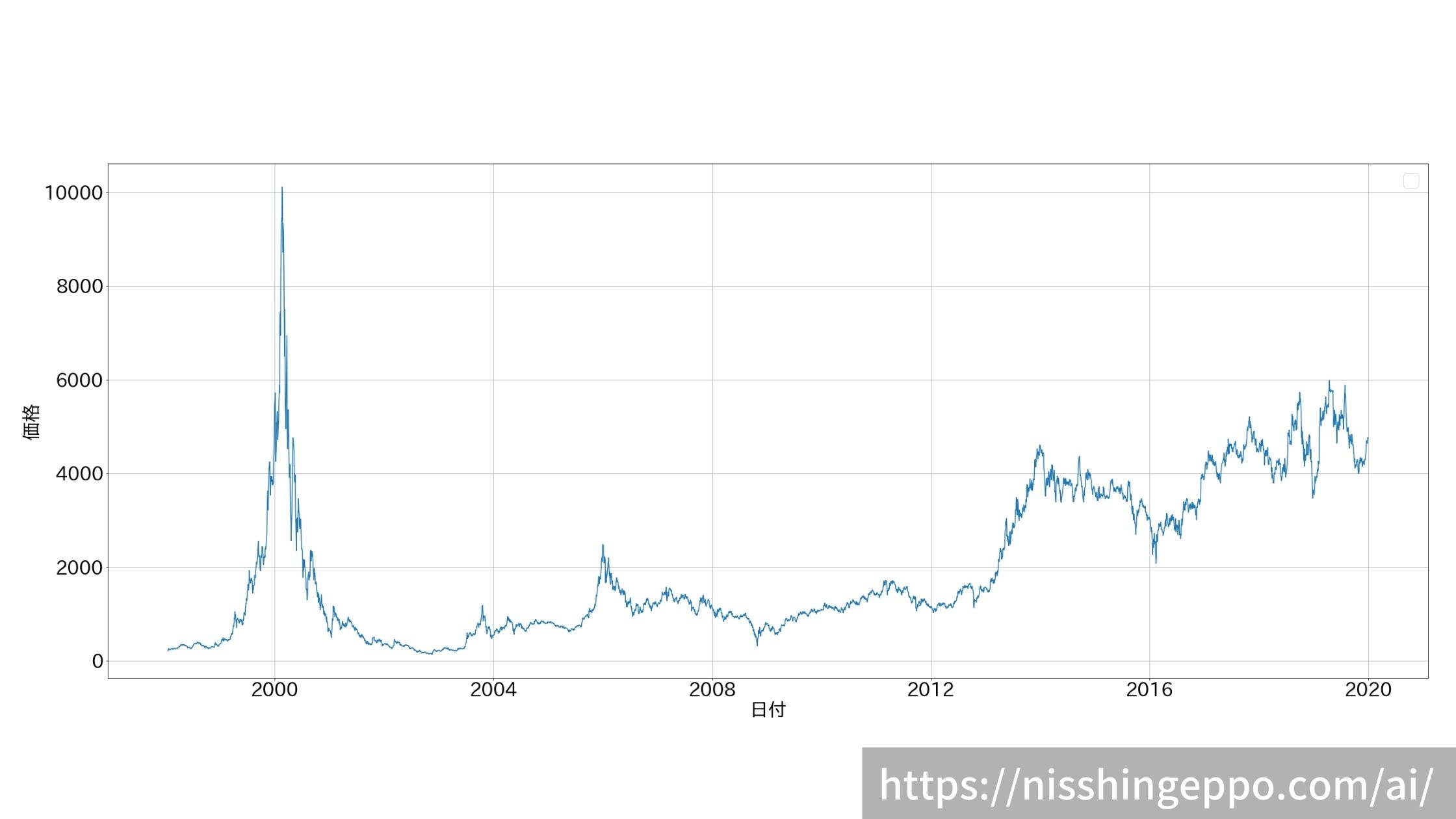
株価をグラフでプロットします。
# プロット
fig, ax = plt.subplots(figsize=(40, 16))
plt.rcParams["font.size"] = 32
ax.plot(dfs["日付"], dfs["終値調整値"])
ax.set_ylabel("価格")
ax.set_xlabel("日付")
ax.grid(True)
ax.legend()
fig.savefig("image.png")
データの正規化
まずは価格データだけ抽出します。
close_prices = dfs['終値調整値'].values
close_prices
学習させるためにデータを正規化します。
close_prices = close_prices.reshape(-1, 1)
scaler = preprocessing.MinMaxScaler()
close_prices = scaler.fit_transform(close_prices)
close_prices#出力
array([[0.00772085],
[0.01042816],
[0.01283465],
...,
[0.45753535],
[0.46445403],
[0.46305024]])
最大値と最小値を確認してもきちんと正規化できていることが分かります。
print(np.min(close_prices))
print(np.max(close_prices))#出力 0.0 0.9999999999999999
データセットの作成
学習の条件とデータを訓練データとテストデータに分割をします。
# 学習設定
batch_size = 32 # ミニバッチサイズ
n_steps = 50 # 入力系列の長さ
input_size = 1 # 入力の次元
hidden_size = 50 # 中間層のユニット数
output_size = 1 # 出力層の次元
n_epochs = 1000 # エポック数
# データセットの作成(入力系列のサイズにデータを分割)
data = []
for i in range(len(close_prices) - n_steps -1):
data.append(close_prices.reshape(-1)[i: i+n_steps+1])
data = np.array(data, dtype=np.float32)
# 訓練データを入力xと解答yに分割する
# 訓練データとテストデータに分割(行ベクトル)
train_ratio = 0.8
n_train = int(len(close_prices) * train_ratio)#学習用データの数(入力系列のセット数)
x_train, y_train = np.split(data[:n_train], [-1], axis=1)
x_test, y_test = np.split(data[n_train:], [-1], axis=1)
x_train.shape学習で使えるようにデータを行列に変換しています。
# 訓練データとテストデータを1列の行列に変換
x_train = np.reshape(x_train, [-1, n_steps, input_size])
x_test = np.reshape(x_test, [-1, n_steps, input_size])#出力 #x_train.shape (4311, 50, 1) #x_test.shape (1027, 50, 1)
モデルの作成
LSTMのモデルを作成していきます。
inputs = tf.keras.layers.Input(shape=(n_steps, input_size))
lstm = tf.keras.layers.LSTM(hidden_size)(inputs)
output = tf.keras.layers.Dense(output_size)(lstm)
model = tf.keras.Model(inputs, output)
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
model.summary()#出力 Model: "model_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_4 (InputLayer) [(None, 50, 1)] 0 _________________________________________________________________ lstm_3 (LSTM) (None, 50) 10400 _________________________________________________________________ dense_3 (Dense) (None, 1) 51 ================================================================= Total params: 10,451 Trainable params: 10,451 Non-trainable params: 0
モデルの学習
エポック数は1000で学習してみました。
train_history = model.fit(x_train, y_train, batch_size=batch_size, epochs=n_epochs)#出力
Epoch 1/1000
135/135 [==============================] - 2s 6ms/step - loss: 0.0023 - accuracy: 4.6393e-04
Epoch 2/1000
135/135 [==============================] - 1s 6ms/step - loss: 3.9146e-04 - accuracy: 4.6393e-04
Epoch 3/1000
135/135 [==============================] - 0s 3ms/step - loss: 2.8635e-04 - accuracy: 4.6393e-04
Epoch 4/1000
135/135 [==============================] - 0s 2ms/step - loss: 2.5817e-04 - accuracy: 4.6393e-04
Epoch 5/1000
135/135 [==============================] - 1s 4ms/step - loss: 2.4273e-04 - accuracy: 4.6393e-04
Epoch 6/1000
135/135 [==============================] - 1s 6ms/step - loss: 2.1312e-04 - accuracy: 4.6393e-04
Epoch 7/1000
135/135 [==============================] - 1s 6ms/step - loss: 2.0364e-04 - accuracy: 4.6393e-04
:1エポック1秒程度なので、15分くらいで学習は終わりました。
推論
株価の予測をしていきます。
# テストデータに対する予測
prediction = model.predict(x_test)
prediction.shape#出力 (1027, 1)
推論結果は正規化されているので、元の値に戻します。
# 正規化を元に戻す
fixed_predicts = scaler.inverse_transform(prediction)
fixed_test = scaler.inverse_transform(y_test)
データをプロットして結果を確認します。
#プロット用にデータをとりまとめ
result = dfs.loc[:,["日付"]]
result = result.drop(range(0,4362))
result["予測"] = fixed_predicts
result["正解"] = fixed_test
# プロット
fig, ax = plt.subplots(figsize=(40, 16))
plt.rcParams["font.size"] = 32
cols = ["正解", "予測"]
for col in cols:
ax.plot(result["日付"], result[col], label=col)
ax.set_ylabel("終値調整値")
ax.set_xlabel("日付")
ax.grid(True)
ax.legend()
fig.savefig("image.png")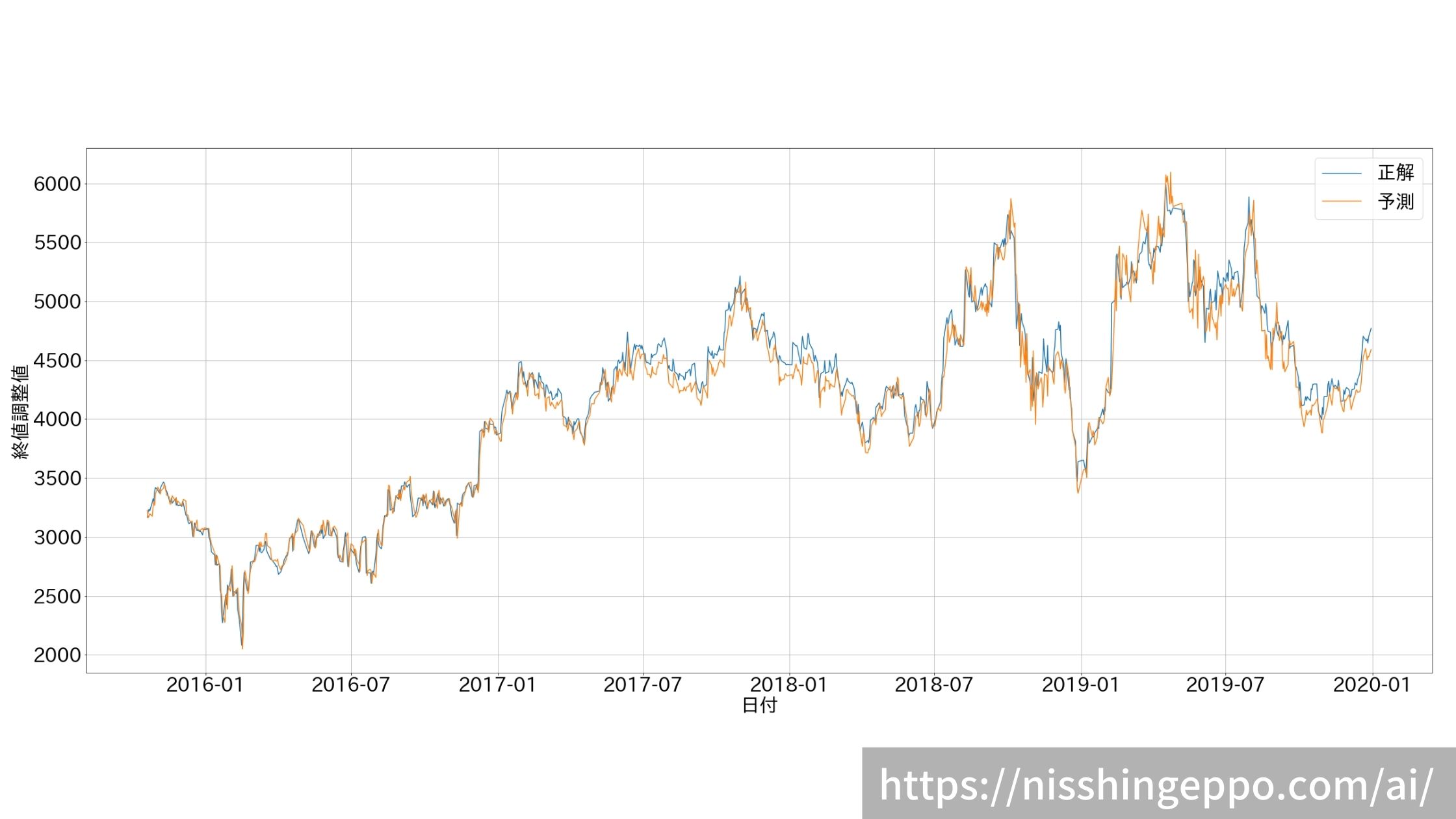
パッと見はちゃんと予測できているように見えますが、正解値の後追いをしているだけのようです。
学習時の推移を確認してみても全く正解率が上がっていないことが分かります。
train_history.history.keys() # ヒストリデータのラベルを見てみる
plt.plot(range(1, n_epochs+1), train_history.history['accuracy'], label="training")
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
fig.savefig("image.png")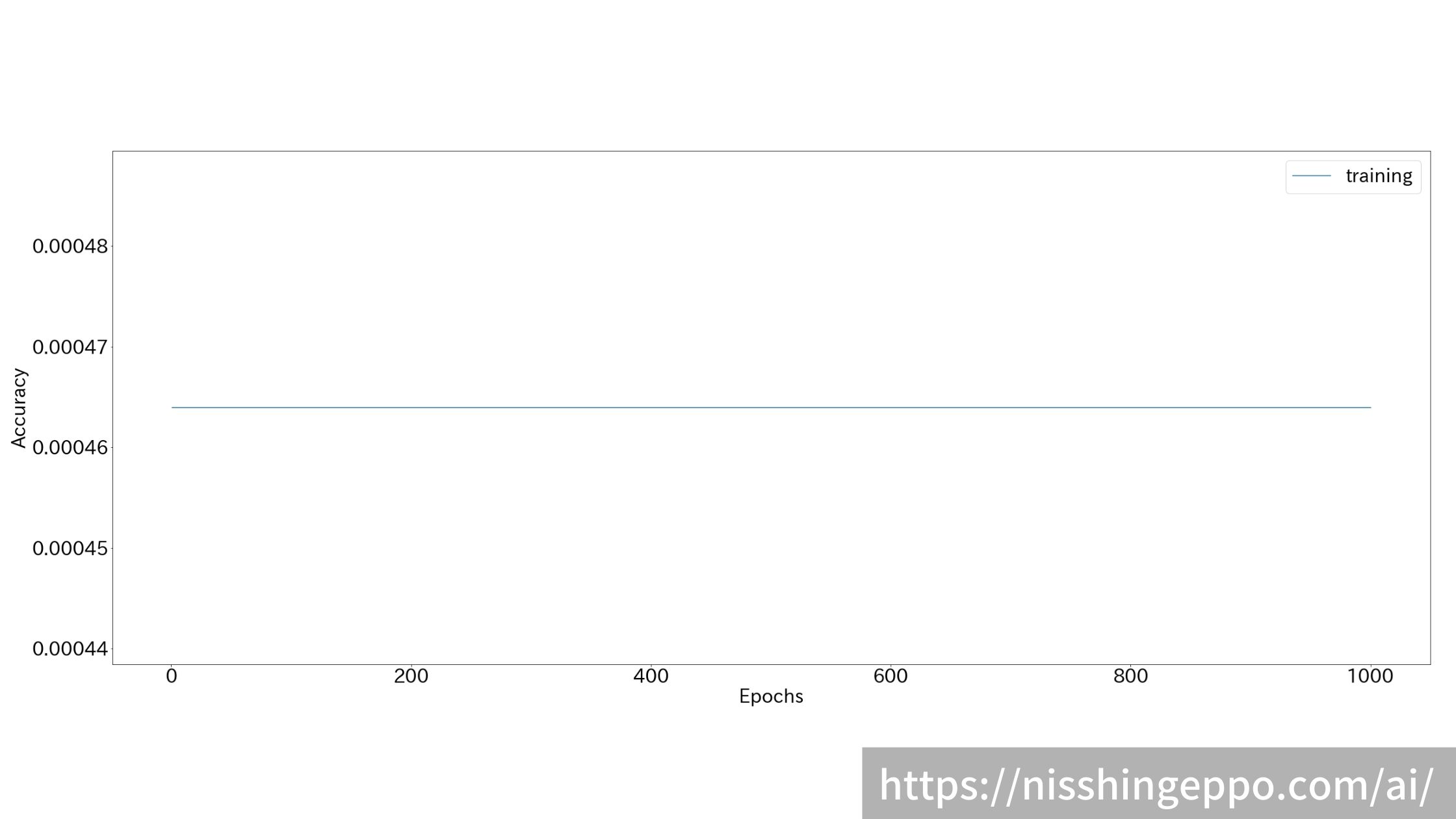
再帰的な予測
前日の正解データを与えず、自分の予想値を入力にしていって再帰的に未来の株価予測をしてみます。
# テストデータの最初のデータからスタートし、モデルの予測を利用し再帰的に予測
curr_x = x_test[0]
predicted = []
# 予測するステップ数
N = 1027
for i in range(N):
# 予測
predicted.append(model.predict(curr_x[None]))
# 入力を更新
curr_x = np.insert(curr_x, n_steps, predicted[-1], axis=0)[1:]
# 正規化を元に戻す
predicted = np.array(predicted, dtype=np.float32)
predicted = predicted.reshape(-1, 1)
fixed_predicts = scaler.inverse_transform(predicted)
result["再帰的予測"] = fixed_predicts
# プロット
fig, ax = plt.subplots(figsize=(40, 16))
plt.rcParams["font.size"] = 32
cols = ["正解", "再帰的予測"]
for col in cols:
ax.plot(result["日付"], result[col], label=col)
ax.set_ylabel("終値調整値")
ax.set_xlabel("日付")
ax.grid(True)
ax.legend()
fig.savefig("image.png")
result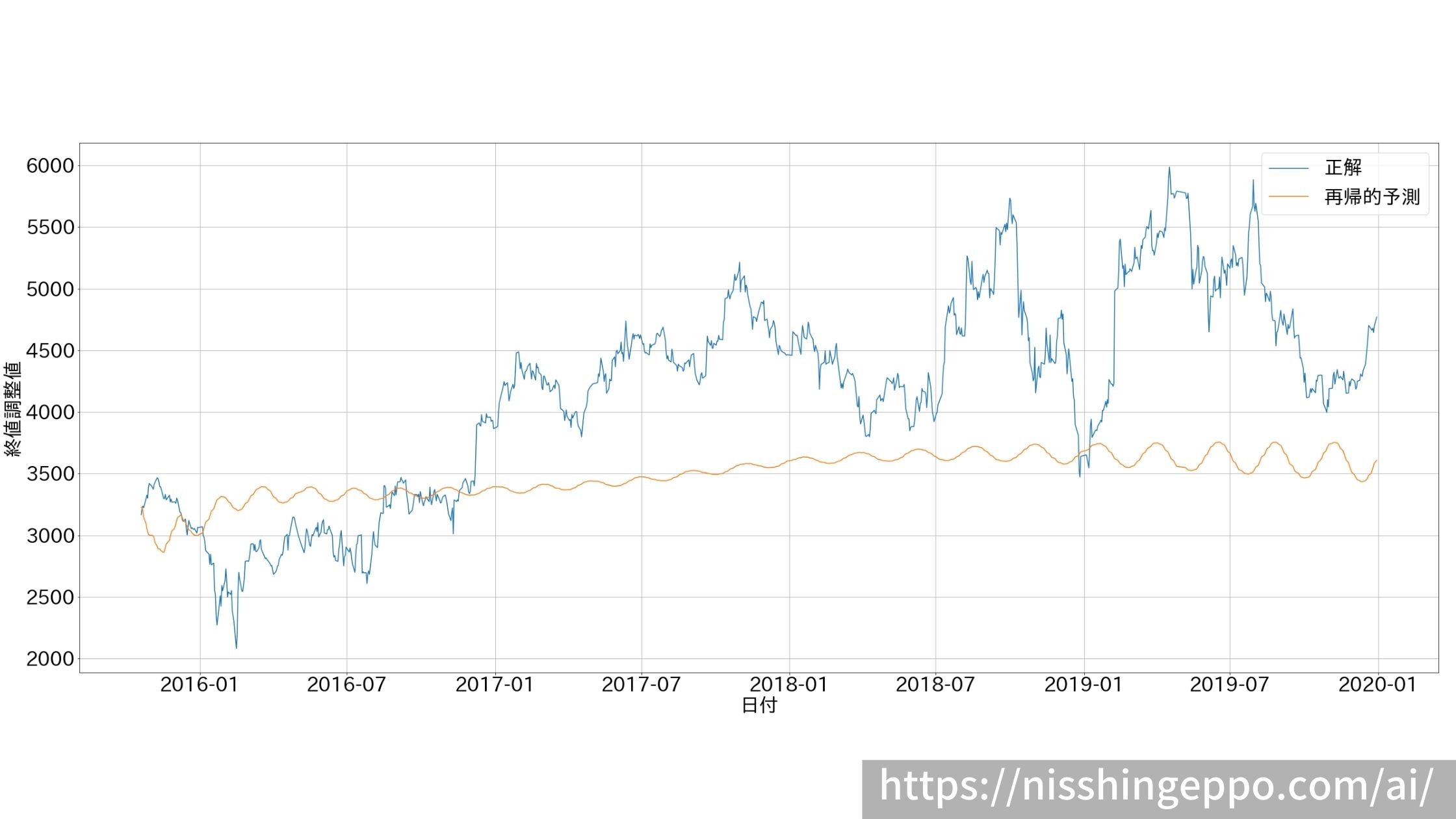
ある値を中心に振動しているだけで、全然推測ができていないことが分かります。
まとめ
LSTMを使って株価の予測をしてみました。
そもそも前提として前日までの株価データだけでは、未来の株価を予測するのはできないか難しすぎるのだと思います。
他の指標も特徴量として追加してあげれば、LSTMでの予測精度ももう少し向上するはずです。
未来の株価をピンポイントで予測する必要もないのでモデル改善をすることで、予測できる課題となるのかもしれません。
金融に関する知識も勉強しながら次の実験をしていきます。
参考文献



コメント