

















- 特徴量(移動平均・価格変化率・ヒストリカルボラティリティ)の生成と影響度の確認
AI(機械学習)を使った株価分析を勉強しながら実践していく、実験ノートのような記事となります。
データ分析の経験は全くなく手探りで進めていくので、温かい目で見ていただきたいです。
コメントやアドバイスなどいただけると非常に助かります。
概要
時系列データは定常性を意識した特徴量設計をすることが重要らしいので、目的変数を価格変化率にした予測を行ってみました。
検証は1998年~2019年のソフトバンクの株価データを使用しました。
やったこと
まずは初期設定
ライブラリのインポート
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn.ensemble import (
ExtraTreesRegressor,
GradientBoostingRegressor,
RandomForestRegressor,
)
import shap
import xgboost
表示設定を変更
%matplotlib inline
pd.options.display.max_rows = 100
pd.options.display.max_columns = 100
pd.options.display.width = 120
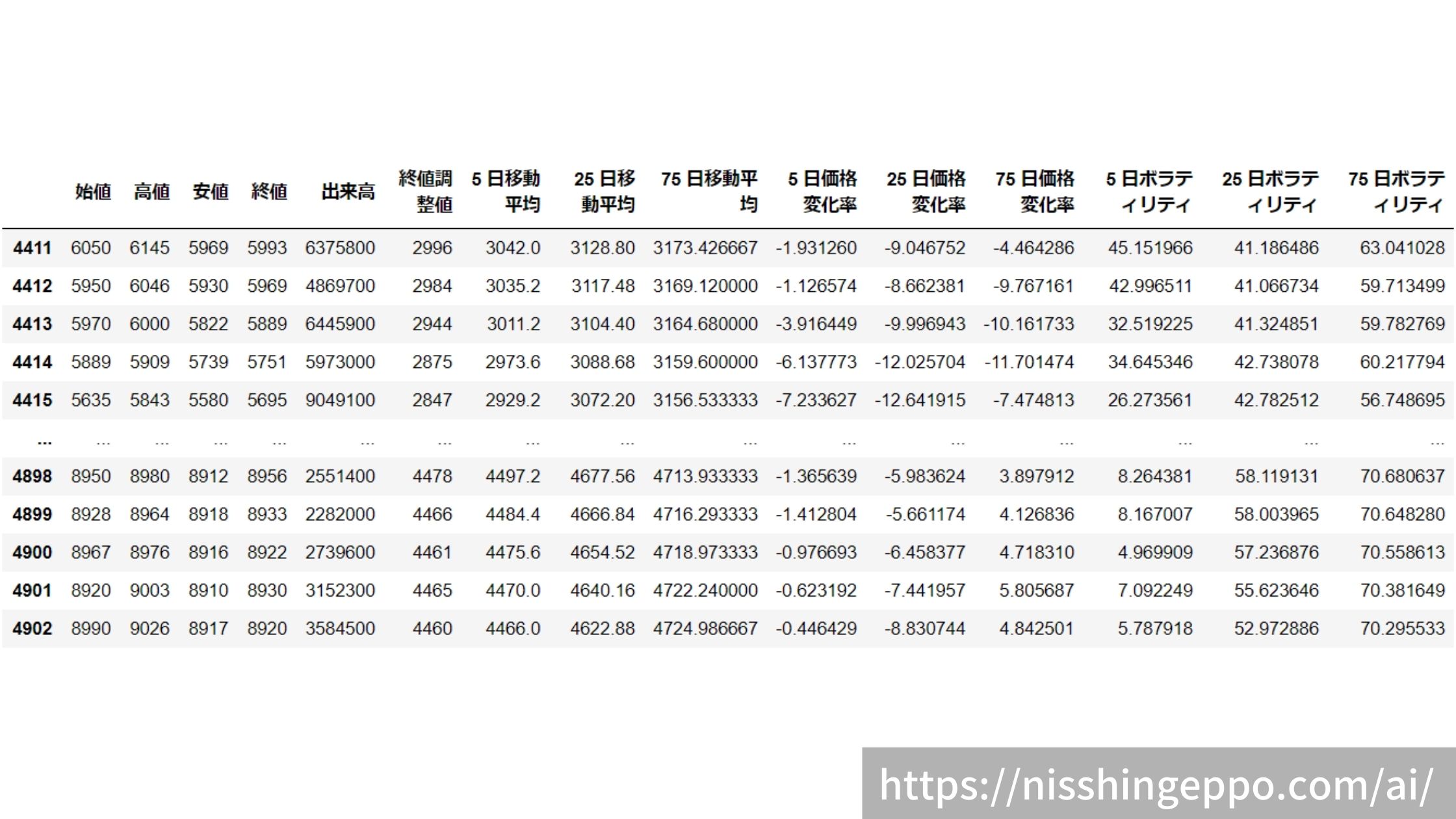
データの確認
データを読み込みます。
# データセット保存先ディレクトリ
data_dir="/path/to"
# 読み込むファイルを定義します。
data_file = f"{data_dir}/9984.csv"
# ファイルを読み込みます
dfs = pd.read_csv(data_file, header=None)
dfs.columns =["日付","始値","高値","安値","終値","出来高","終値調整値"]
# カラムの型を修正
dfs[["始値","高値","安値","終値","出来高","終値調整値"]] = dfs[["始値","高値","安値","終値","出来高","終値調整値"]].astype(int)
dfs["日付"] = pd.to_datetime(dfs["日付"])
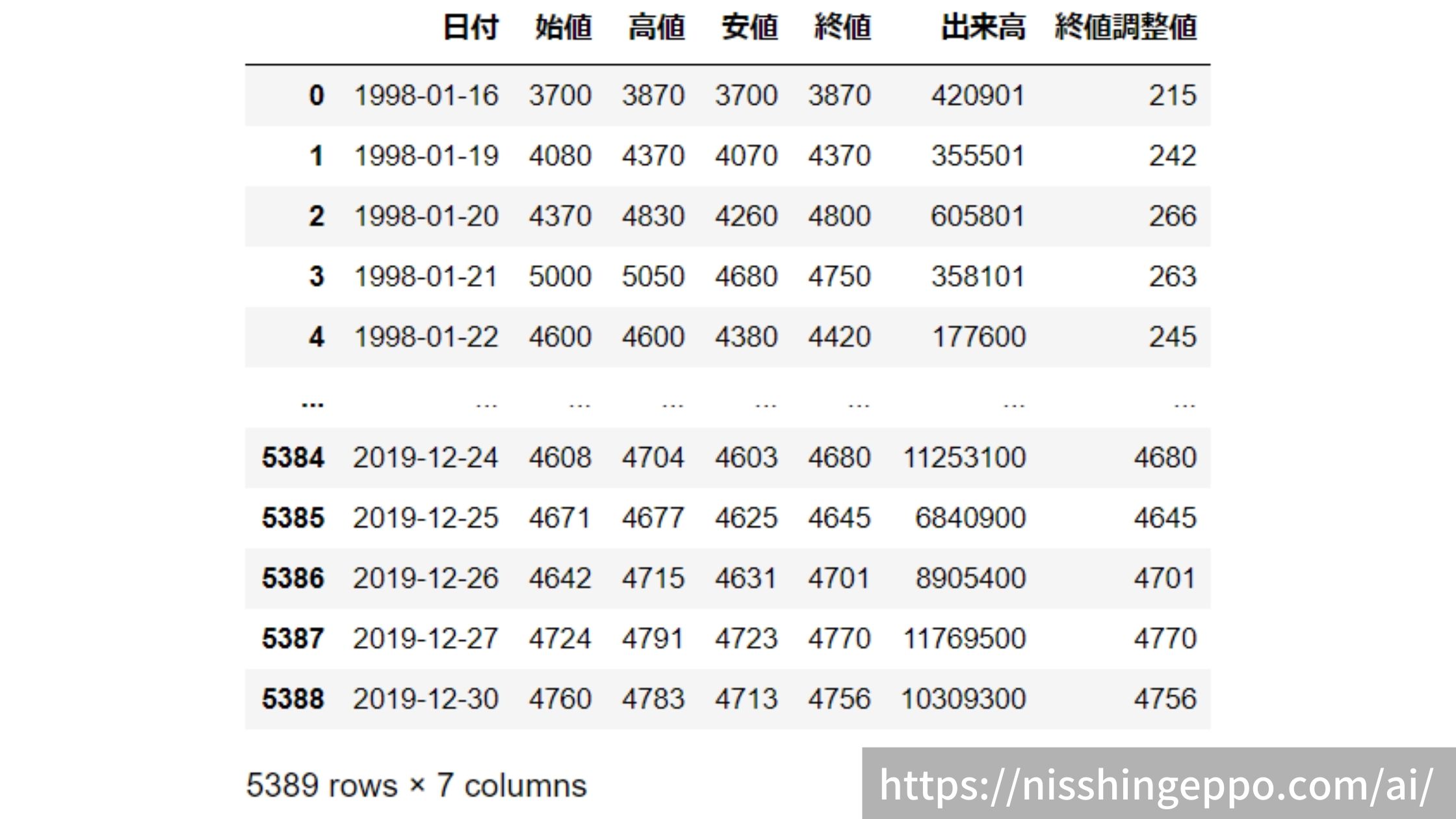
dfs
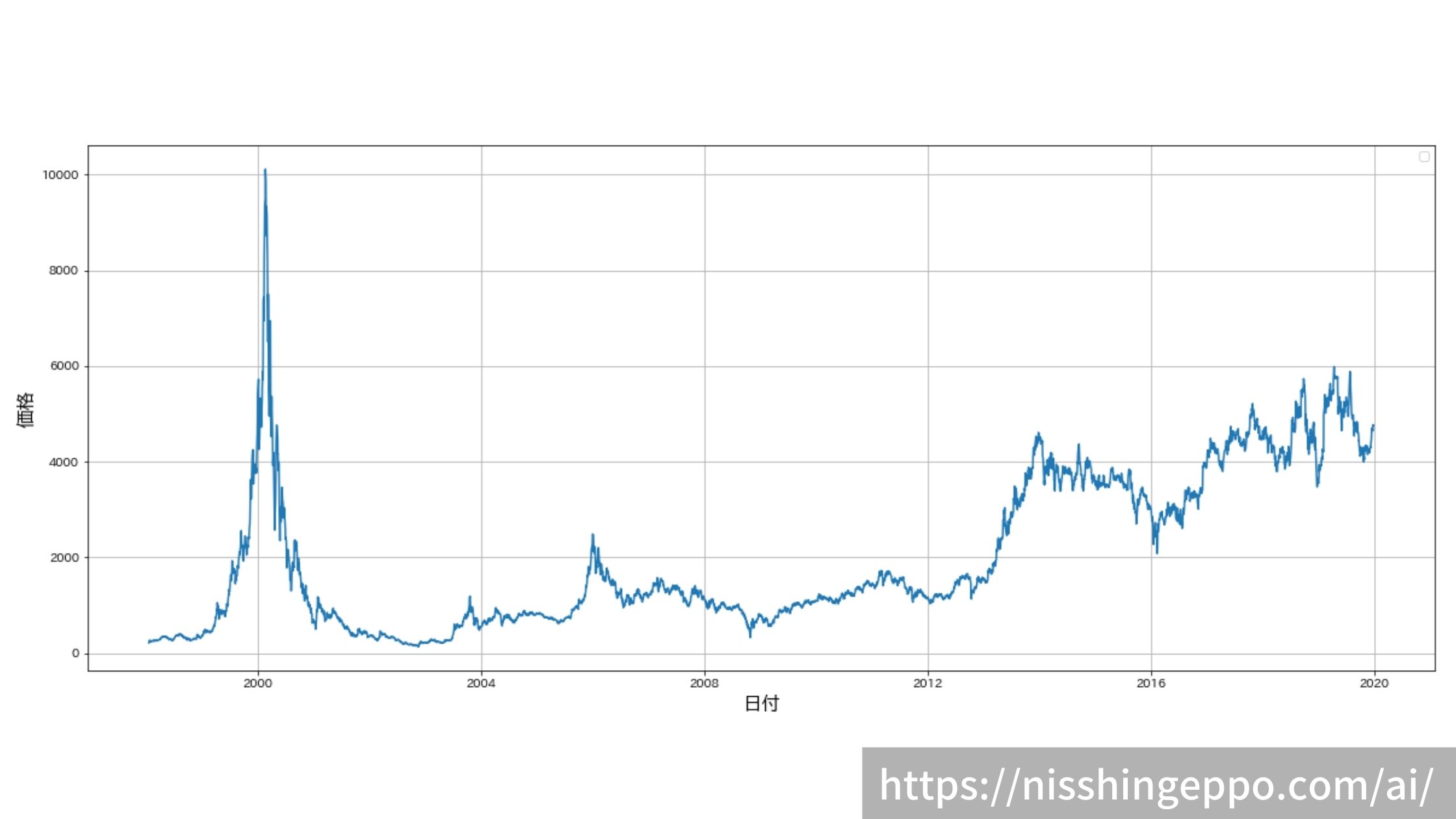
株価をグラフでプロットします。
# プロット
fig, ax = plt.subplots(figsize=(20, 8))
ax.plot(dfs["日付"], dfs["終値調整値"])
ax.set_ylabel("終値調整値")
ax.set_xlabel("日付")
ax.grid(True)
ax.legend()
fig.savefig("image.png")
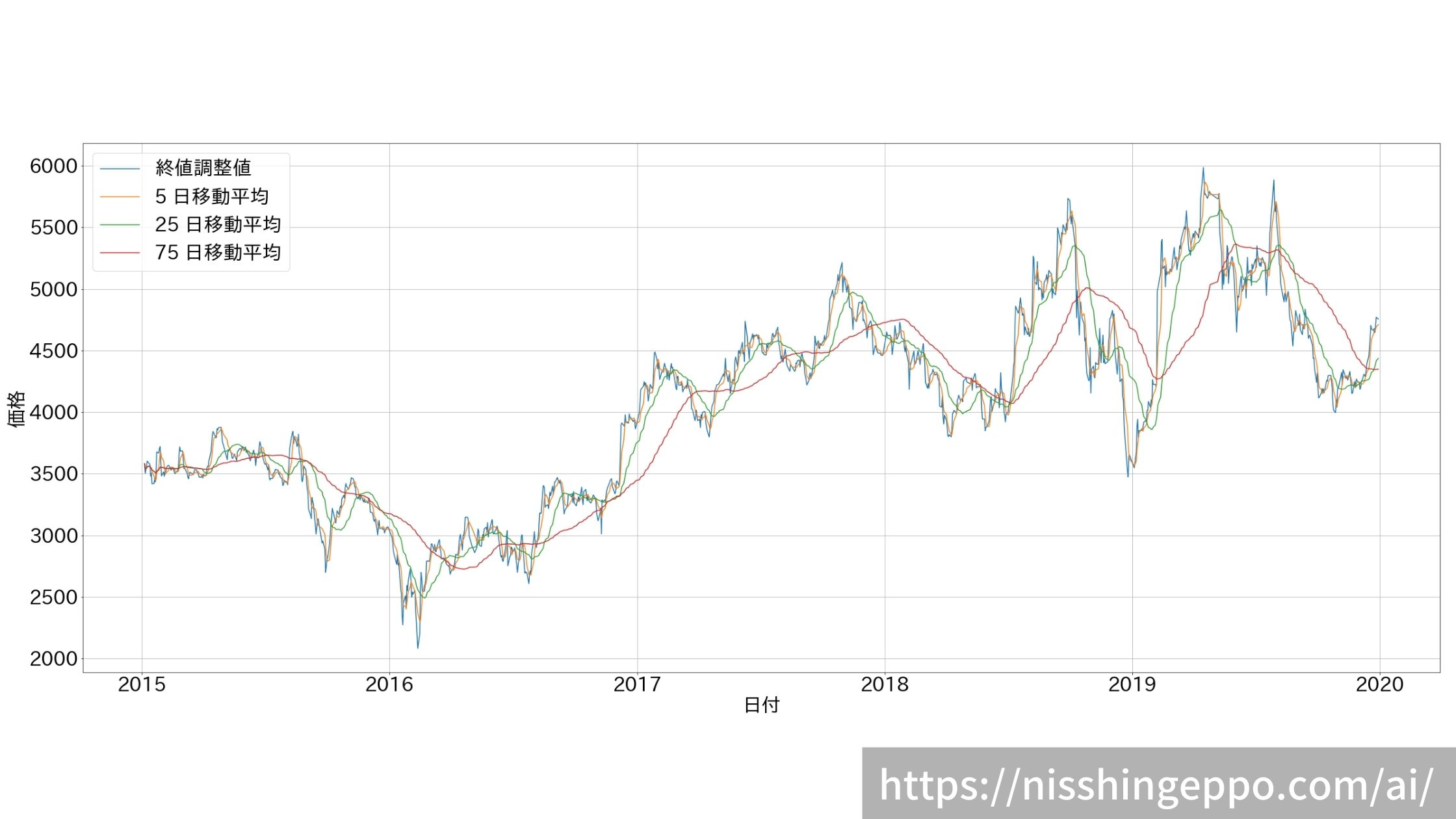
【特徴量1】移動平均を作成
データ量が多いので、3年分のデータで移動平均を計算しました。
# 対象期間のデータ読み込み
price_data = dfs.loc[dfs["日付"] > pd.datetime(2015,1,1)].copy()
# 5日、25日、75日の価格変化率を算出
periods = [5, 25, 75]
ma_cols = ["終値調整値"]
for period in periods:
col = "{} 日移動平均".format(period)
price_data[col] = price_data["終値調整値"].rolling(period, min_periods=1).mean()
ma_cols.append(col)
# プロット
fig, ax = plt.subplots(figsize=(40, 16))
plt.rcParams["font.size"] = 32
for col in ma_cols:
ax.plot(price_data["日付"], price_data[col], label=col)
ax.set_ylabel("価格")
ax.set_xlabel("日付")
ax.grid(True)
ax.legend()
fig.savefig("image.png")
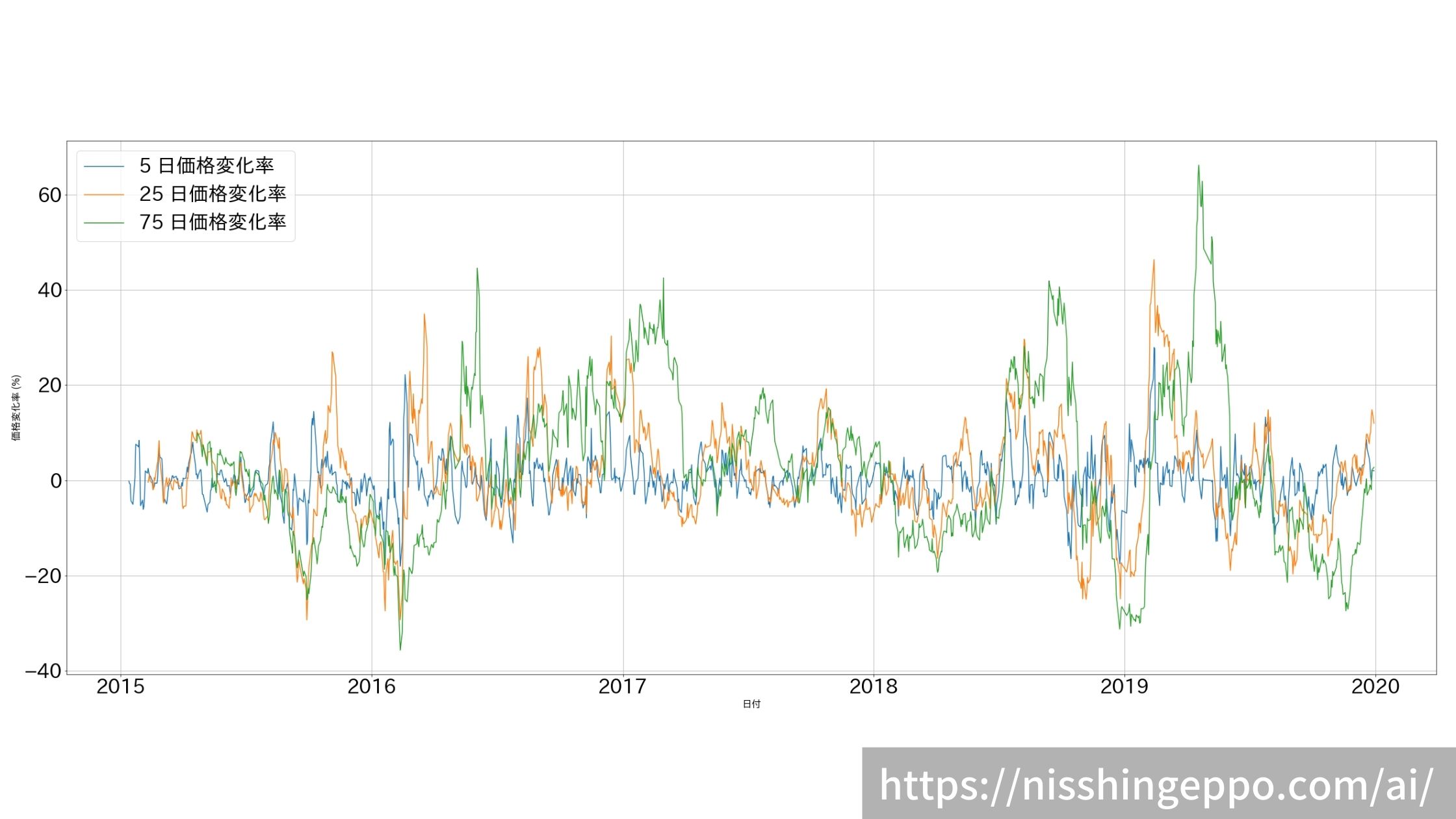
【特徴量2】価格変化率を作成
続いて、価格変化率を計算しました。
# 5日、25日、75日の価格変化率を算出
periods = [5, 25, 75]
return_cols = []
for period in periods:
col = "{} 日価格変化率".format(period)
price_data[col] = price_data["終値調整値"].pct_change(period) * 100
return_cols.append(col)
# プロット
fig, ax = plt.subplots(figsize=(40, 16))
plt.rcParams["font.size"] = 32
for col in return_cols:
ax.plot(price_data["日付"], price_data[col], label=col)
ax.set_ylabel("価格変化率 (%)",fontsize=16)
ax.set_xlabel("日付",fontsize=16)
ax.grid(True)
ax.legend()
fig.savefig("image.png")
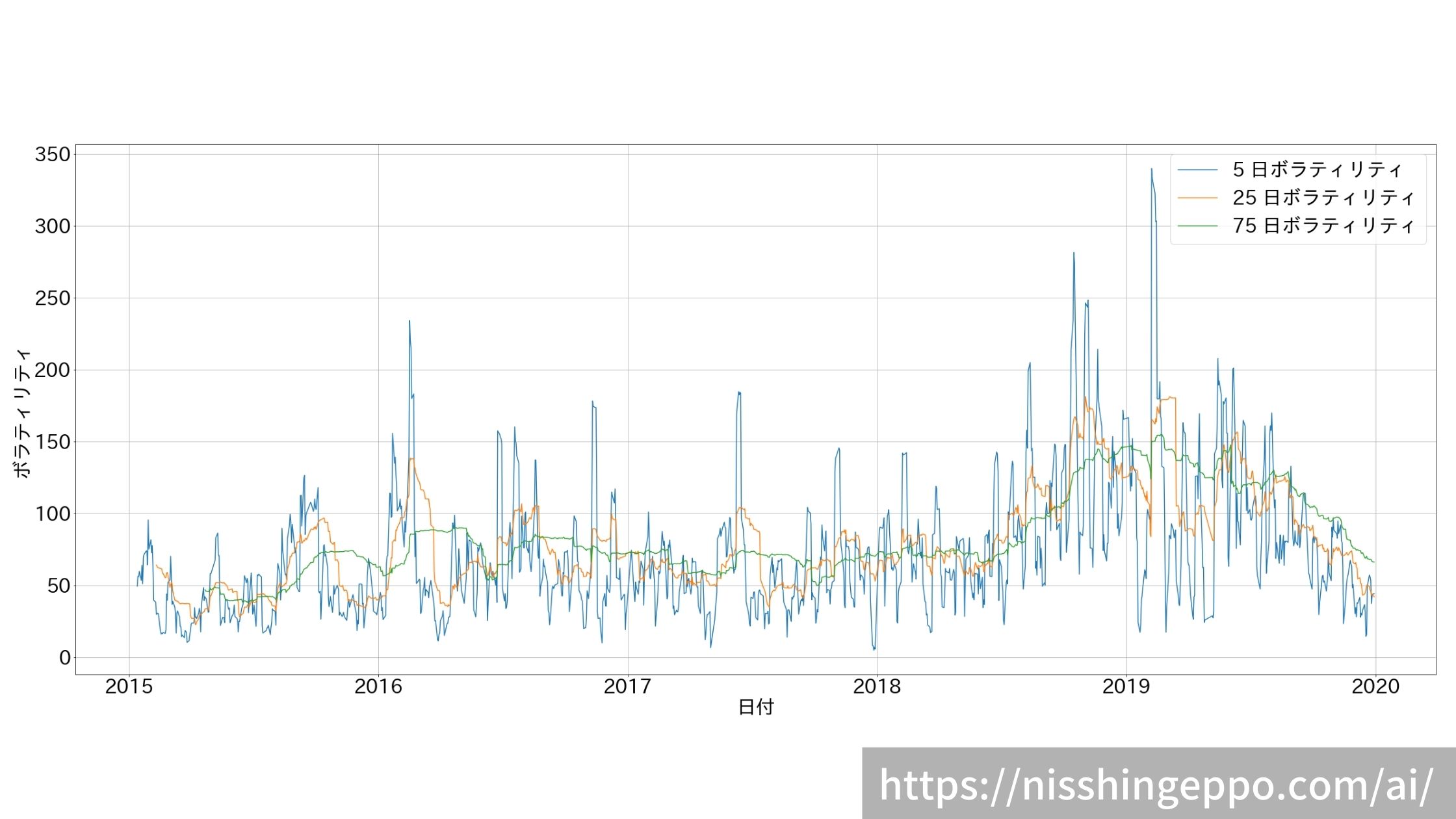
【特徴量3】ヒストリカル・ボラティリティを作成
3年分のデータでヒストリカル・ボラティリティを計算しました。
# 5日、25日、75日の価格変化率を算出
periods = [5, 25, 75]
vol_cols = []
for period in periods:
col = "{} 日ボラティリティ".format(period)
price_data[col] = price_data["終値調整値"].diff().rolling(period).std()
vol_cols.append(col)
# プロット
fig, ax = plt.subplots(figsize=(40, 16))
plt.rcParams["font.size"] = 32
for col in vol_cols:
ax.plot(price_data["日付"], price_data[col], label=col)
ax.set_ylabel("ボラティリティ")
ax.set_xlabel("日付")
ax.grid(True)
ax.legend()
fig.savefig("image.png")
作った特徴量を同時にプロットして比較
生成した特徴量を縦に並べることで、株価に変化があったタイミングの前に予兆がなかったかなどデータ分析をしやすくなります。
# プロット
fig, ax = plt.subplots(nrows=3 ,figsize=(40, 16))
plt.rcParams["font.size"] = 18
for col in ma_cols:
ax[0].plot(price_data["日付"], price_data[col], label=col)
for col in return_cols:
ax[1].plot(price_data["日付"], price_data[col], label=col)
for col in vol_cols:
ax[2].plot(price_data["日付"], price_data[col], label=col)
ax[0].set_ylabel("価格",fontsize=16)
ax[1].set_ylabel("価格変化率 (%)")
ax[2].set_ylabel("ボラティリティ")
for _ax in ax:
_ax.set_xlabel("日付")
_ax.grid(True)
_ax.legend()
fig.savefig("image.png")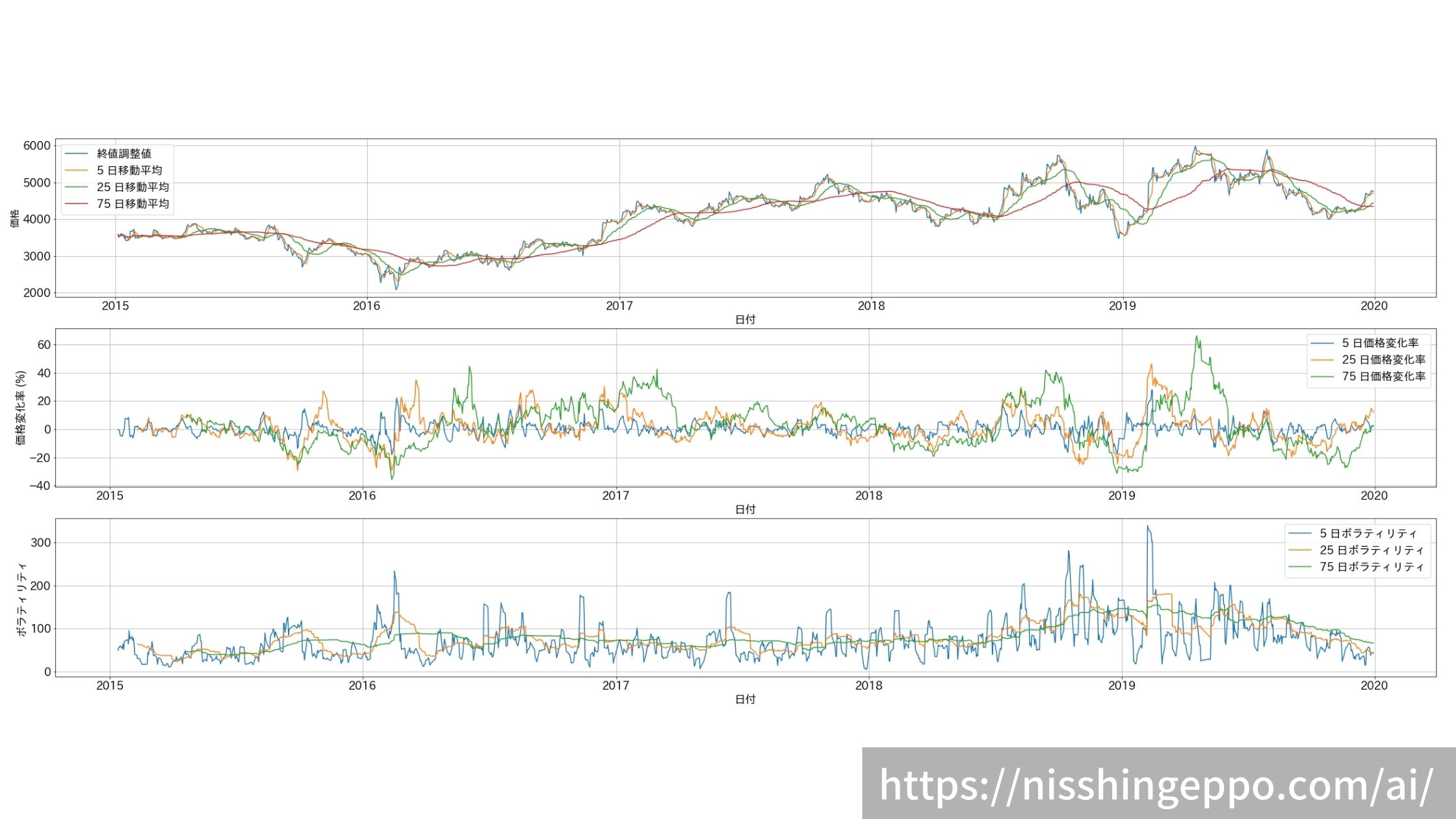
【目的変数】明日の株価の変化率を作成
明日の株価を知りたいので、目的変数には1日後の価格変化率を作ります。
目的変数を数式で表すと以下のようになります。
$$ (目的変数) = \frac{(明日の株価) - (今日の株価)}{ (今日の株価) } $$
# 1日後の価格変化率を算出
periods = [1]
predict_term = 1
for period in periods:
col = "{} 日後の{} 日価格変化率".format(predict_term,period)
price_data[col] = price_data["終値調整値"].pct_change(period) * 100
price_data[col] = price_data[col].shift(periods=-predict_term)
ついでに1日後の価格も作っておきます。
# 目的変数に対応する日の価格も作っておく
for period in periods:
col = "{} 日後の終値調整値".format(predict_term)
price_data[col] = price_data["終値調整値"].shift(periods=-predict_term)
データの前処理
欠損値を0で穴埋めして処理しておきます。
元データには欠損はありませんが、変化率やボラティリティを作った際に最初の数日分は欠損するため処理しました。
# 欠損値処理
price_data = price_data.fillna(0)
price_data = price_data.replace([np.inf, -np.inf], 0)
学習用・検証用・テスト用にデータを分割する
データセットの分割をします。
学習データは2年分、バリデーションデータは1年分、テストデータは1年分という配分にしました。
TRAIN_START = "2016-01-01"
TRAIN_END = "2017-12-31"
VAL_START = "2018-02-01"
VAL_END = "2018-12-01"
TEST_START = "2019-01-01"
TEST_END = "2019-10-30"目的変数を作成したら、リークしないように元データから目的変数を削除しています。
# 目的変数データ作成
train_Y = price_data.loc[:, ["日付", "終値調整値", "1 日後の終値調整値", "1 日後の1 日価格変化率"]].loc[(TRAIN_START < price_data["日付"]) & (price_data["日付"] < TRAIN_END)].copy()
val_Y = price_data.loc[:, ["日付", "終値調整値","1 日後の終値調整値", "1 日後の1 日価格変化率"]].loc[(VAL_START < price_data["日付"]) & (price_data["日付"] < VAL_END)].copy()
test_Y = price_data.loc[:, ["日付", "終値調整値","1 日後の終値調整値", "1 日後の1 日価格変化率"]].loc[(TEST_START < price_data["日付"]) & (price_data["日付"] < TEST_END)].copy()
# 目的変数を削除
price_data = price_data.drop(["1 日後の1 日価格変化率"], axis=1)
price_data = price_data.drop(["1 日後の終値調整値"], axis=1)次に特徴量のデータセットを作成しています。
日付はdate型で学習するとエラーになるので削除しています。
# 説明変数データ作成
train_X = price_data.loc[(TRAIN_START < price_data["日付"]) & (price_data["日付"] < TRAIN_END)].copy()
val_X = price_data.loc[(VAL_START < price_data["日付"]) & (price_data["日付"] < VAL_END)].copy()
test_X = price_data.loc[(TEST_START < price_data["日付"]) & (price_data["日付"] < TEST_END)].copy()
# 日付データ削除
train_X = train_X.drop(["日付"], axis=1)
val_X = val_X.drop(["日付"], axis=1)
test_X = test_X.drop(["日付"], axis=1)
特徴量は以下のものが使われています。
モデルの学習
今回はランダムフォレストを使って検証してみました。
# 目的変数を指定
label = "1 日後の1 日価格変化率"
# モデルの初期化
pred_model = RandomForestRegressor(random_state=0)
# モデルの学習
pred_model.fit(train_X.values, train_Y[label].values)
ランダムフォレストについてはこちらの記事で解説しています。

推論(バリデーションデータ)
ようやく株価変化率の予測です。
result = val_Y
result["予測"] = pred_model.predict(val_X)
# プロット
fig, ax = plt.subplots(figsize=(40, 16))
plt.rcParams["font.size"] = 32
cols = ["1 日後の1 日価格変化率", "予測"]
for col in cols:
ax.plot(result["日付"], result[col], label=col)
ax.set_ylabel("価格変化率")
ax.set_xlabel("日付")
ax.grid(True)
ax.legend()
fig.savefig("image.png")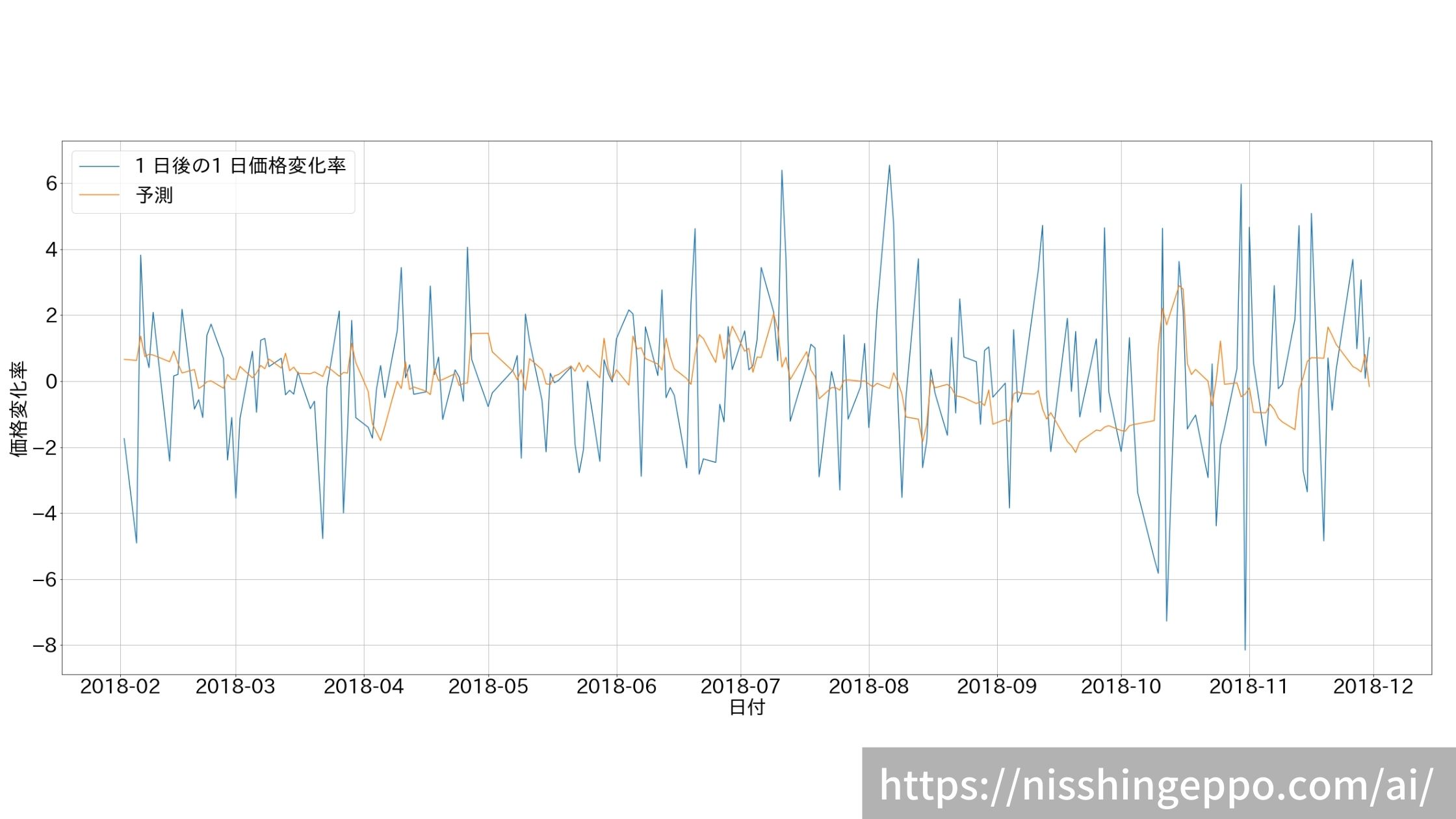
これだけ見てもわからないので、予測と正解を散布図にしてみます。
plt.rcParams["font.size"] = 20
fig = sns.jointplot( x=result["予測"], y=result["1 日後の1 日価格変化率"])
fig.savefig("image.png")
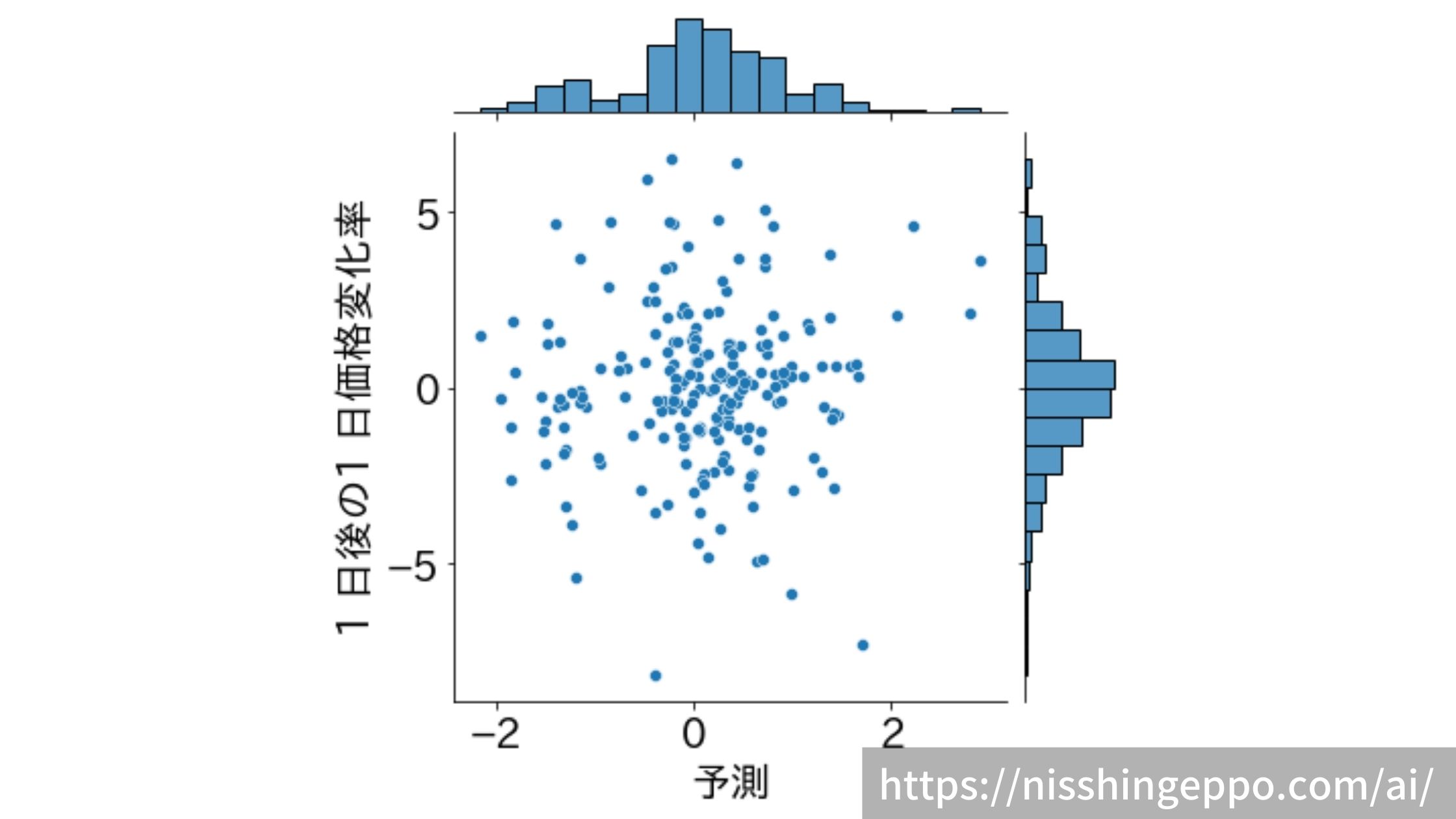
あまり相関はなさそうです。
変化率だけでなく株価もプロットしてみました。
result["予測"] = (result["予測"] + 100) /100
result["1日後の予想価格"] = result["終値調整値"]*result["予測"]
# プロット
fig, ax = plt.subplots(figsize=(40, 16))
plt.rcParams["font.size"] = 32
cols = ["1 日後の終値調整値", "1日後の予想価格"]
for col in cols:
ax.plot(result["日付"], result[col], label=col)
ax.set_ylabel("価格",fontsize=16)
ax.set_xlabel("日付",fontsize=16)
ax.grid(True)
ax.legend()
fig.savefig("image.png")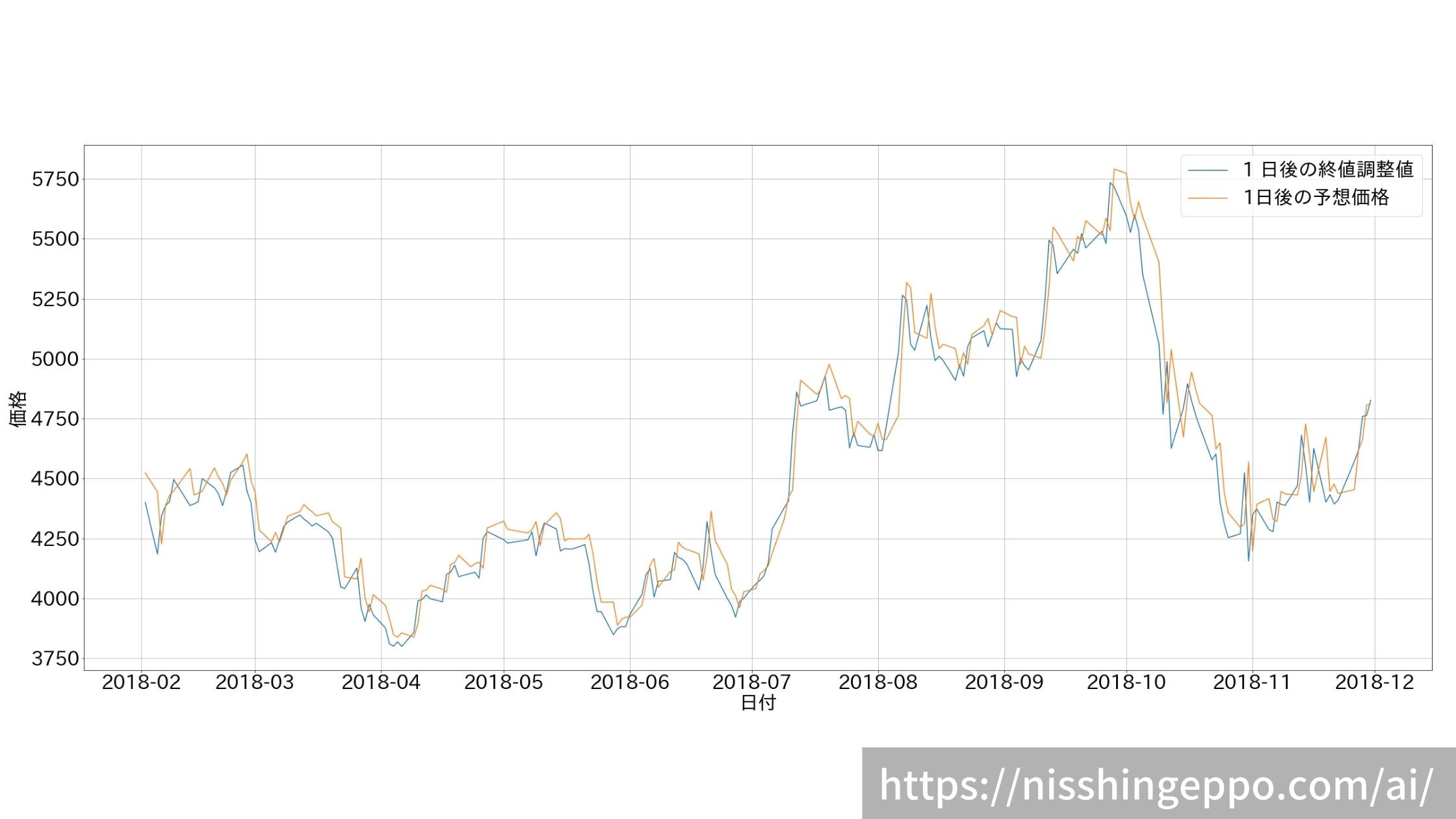
予測結果に対する分析
推論に使った特徴量の重要度を測定します。
# 学習済みモデルを指定
rf = pred_model
# 重要度順を取得
sorted_idx = rf.feature_importances_.argsort()
# プロット
fig, ax = plt.subplots(figsize=(20, 20))
plt.rcParams["font.size"] = 32
ax.barh(train_X.columns[sorted_idx], rf.feature_importances_[sorted_idx])
ax.set_xlabel("Random Forest Feature Importance")
fig.savefig("image.png")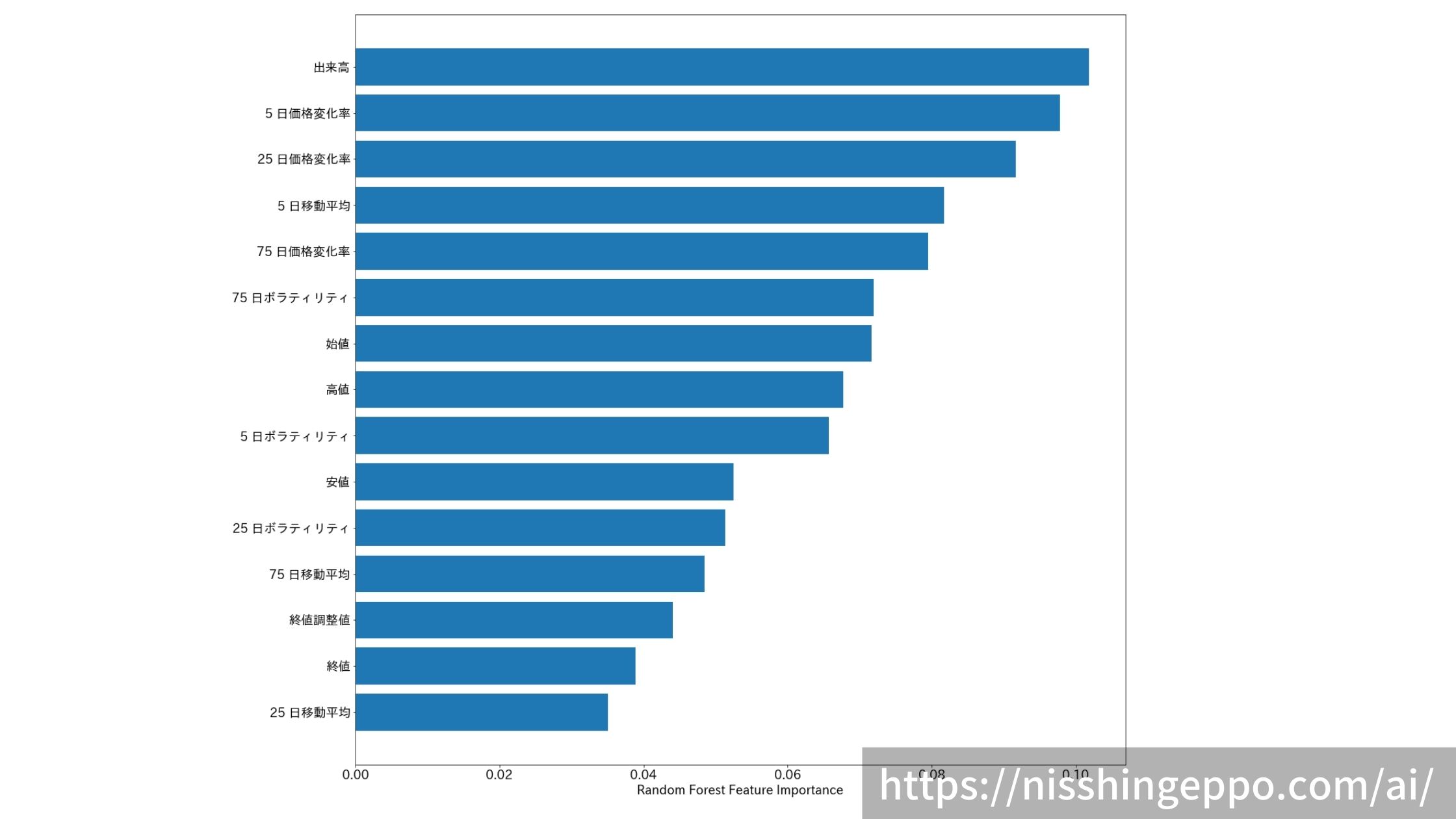
出来高と変化率を元に推論しているようです。
推論(テストデータ)
続いて、テストデータに対して推論をしてみます。
result = test_Y
result["予測"] = pred_model.predict(test_X)
# プロット
fig, ax = plt.subplots(figsize=(40, 16))
plt.rcParams["font.size"] = 32
cols = ["1 日後の1 日価格変化率", "予測"]
for col in cols:
ax.plot(result["日付"], result[col], label=col)
ax.set_ylabel("価格変化率",fontsize=16)
ax.set_xlabel("日付",fontsize=16)
ax.grid(True)
ax.legend()
fig.savefig("image.png")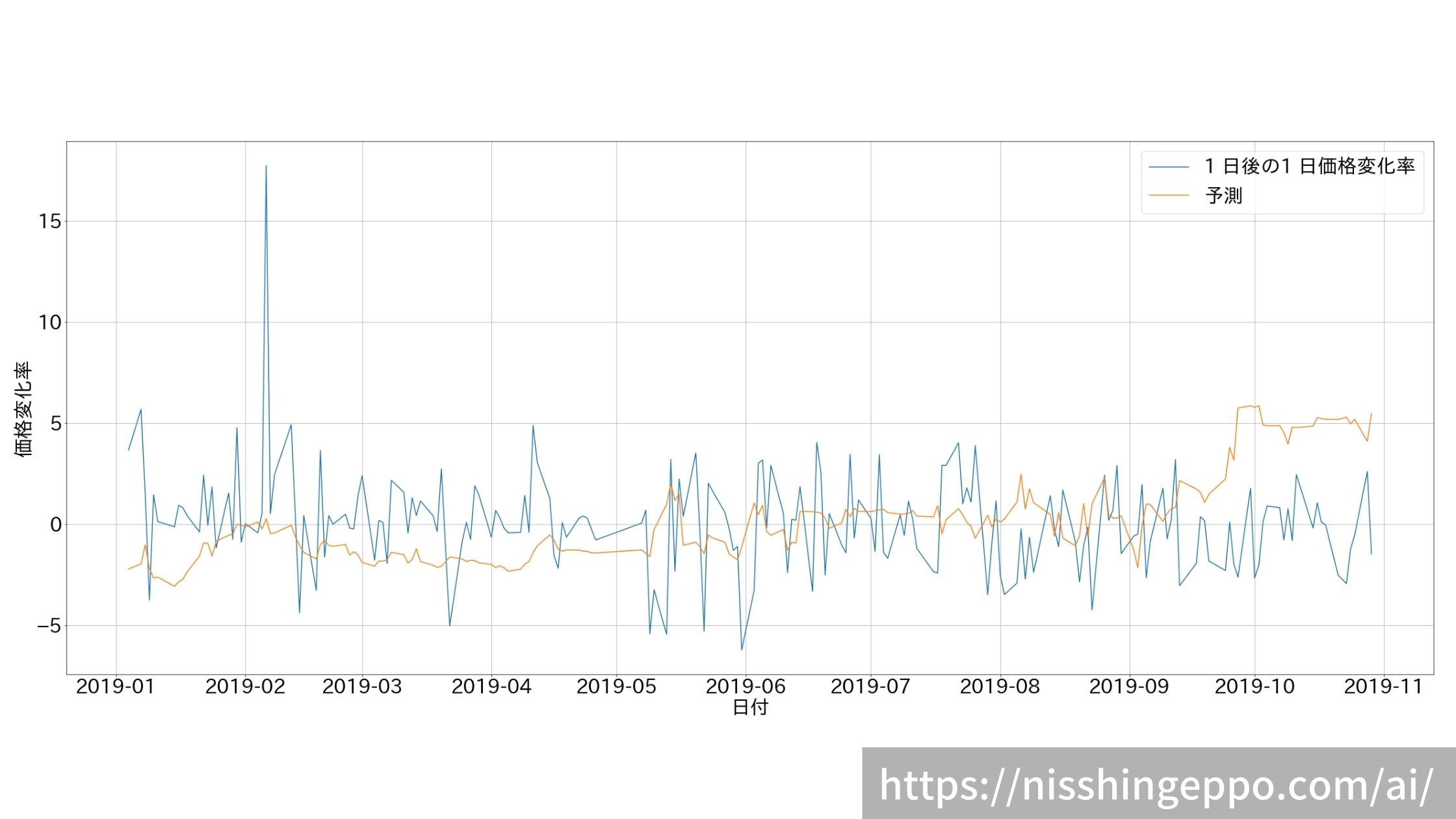
あまりうまく予測できていないように見えます。
予測と正解を散布図で見てみます。
plt.rcParams["font.size"] = 20
sns.jointplot( x=result["予測"], y=result["1 日後の1 日価格変化率"])
fig.savefig("image.png")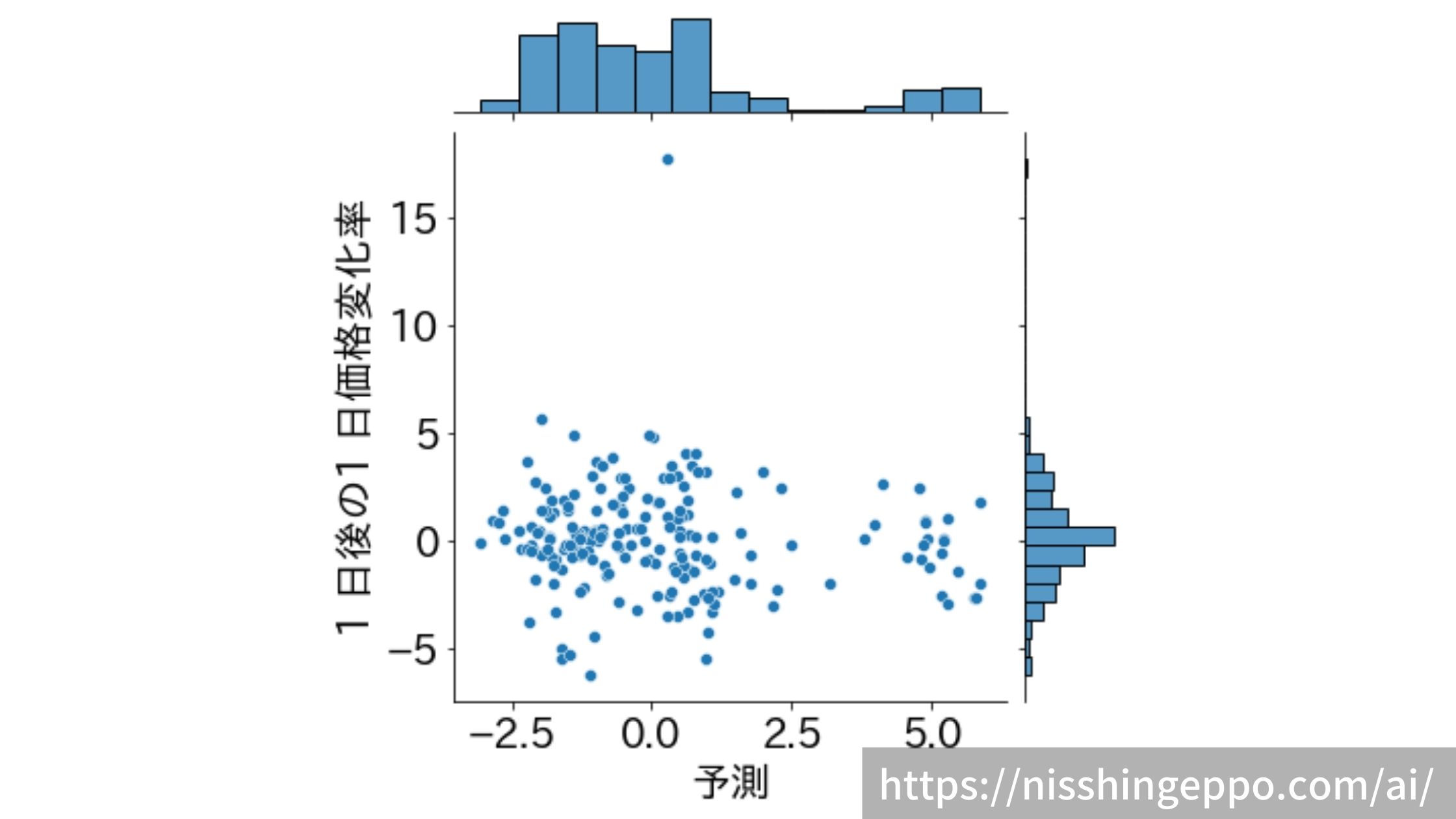
相関が全く見られなくなったように読み取れました。
変化率だけでなく株価もプロットしてみます。
result["予測"] = (result["予測"] + 100) /100
result["1日後の予想価格"] = result["終値調整値"]*result["予測"]
# プロット
fig, ax = plt.subplots(figsize=(40, 16))
plt.rcParams["font.size"] = 32
cols = ["1 日後の終値調整値", "1日後の予想価格"]
for col in cols:
ax.plot(result["日付"], result[col], label=col)
ax.set_ylabel("価格")
ax.set_xlabel("日付")
ax.grid(True)
ax.legend()
fig.savefig("image.png")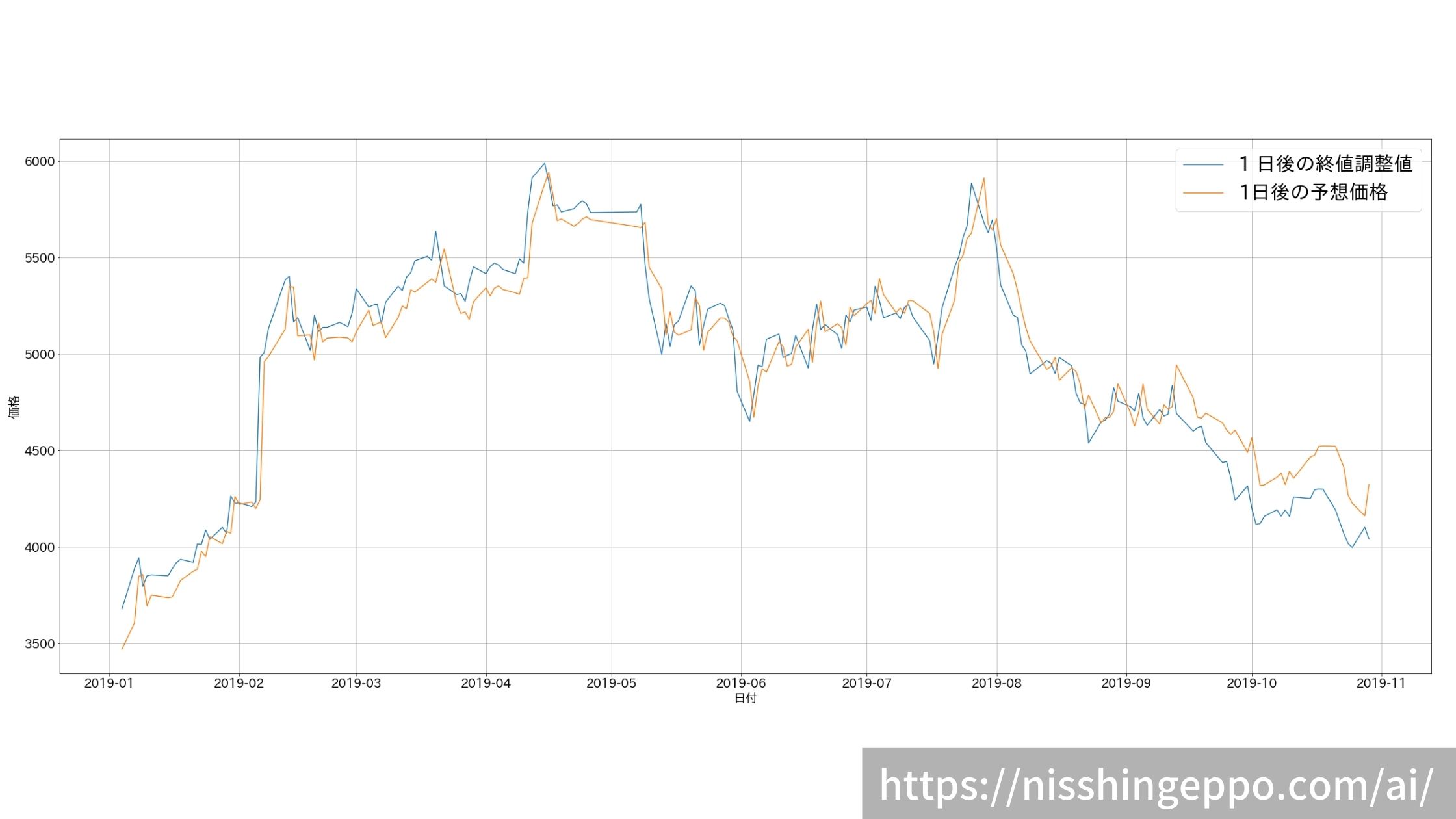
特徴量の影響度を算出
SHAPを使って特徴量が予測値に与えた影響度を算出してみます。
shap.initjs()
explainer = shap.TreeExplainer(model=pred_model, feature_perturbation='tree_path_dependent', model_output='margin')
# SHAP値
shap_values = explainer.shap_values(X=train_X)
# プロット
shap.summary_plot(shap_values, train_X, plot_type="bar",show=False)
matplotlib.pylab.tight_layout() #軸ラベルの調整
plt.savefig("image.png")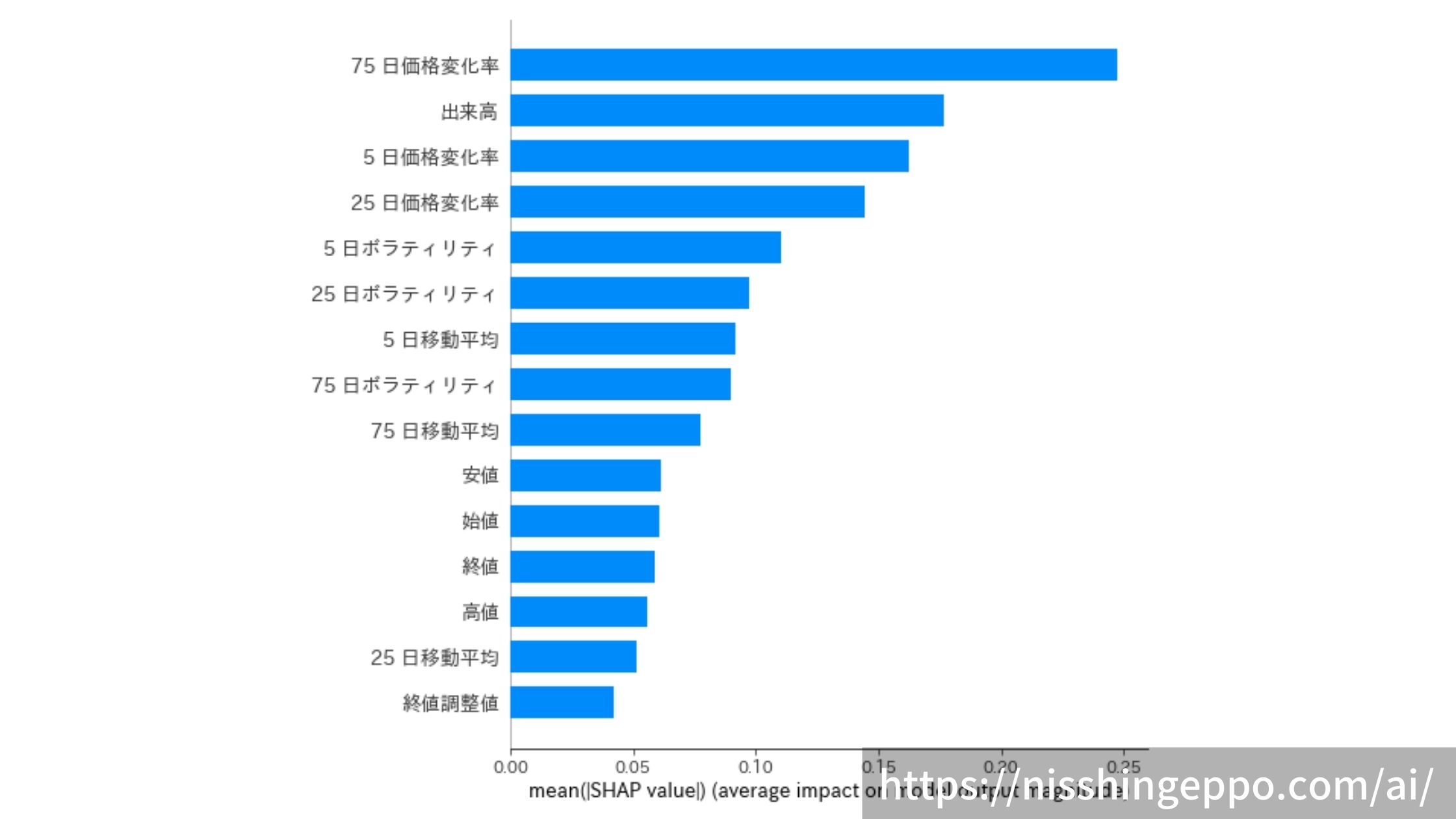
特徴量を少し変化させたときの結果への影響度を確認します。
shap.summary_plot(shap_values, train_X)
matplotlib.pylab.tight_layout() #軸ラベルの調整
plt.savefig("image.png")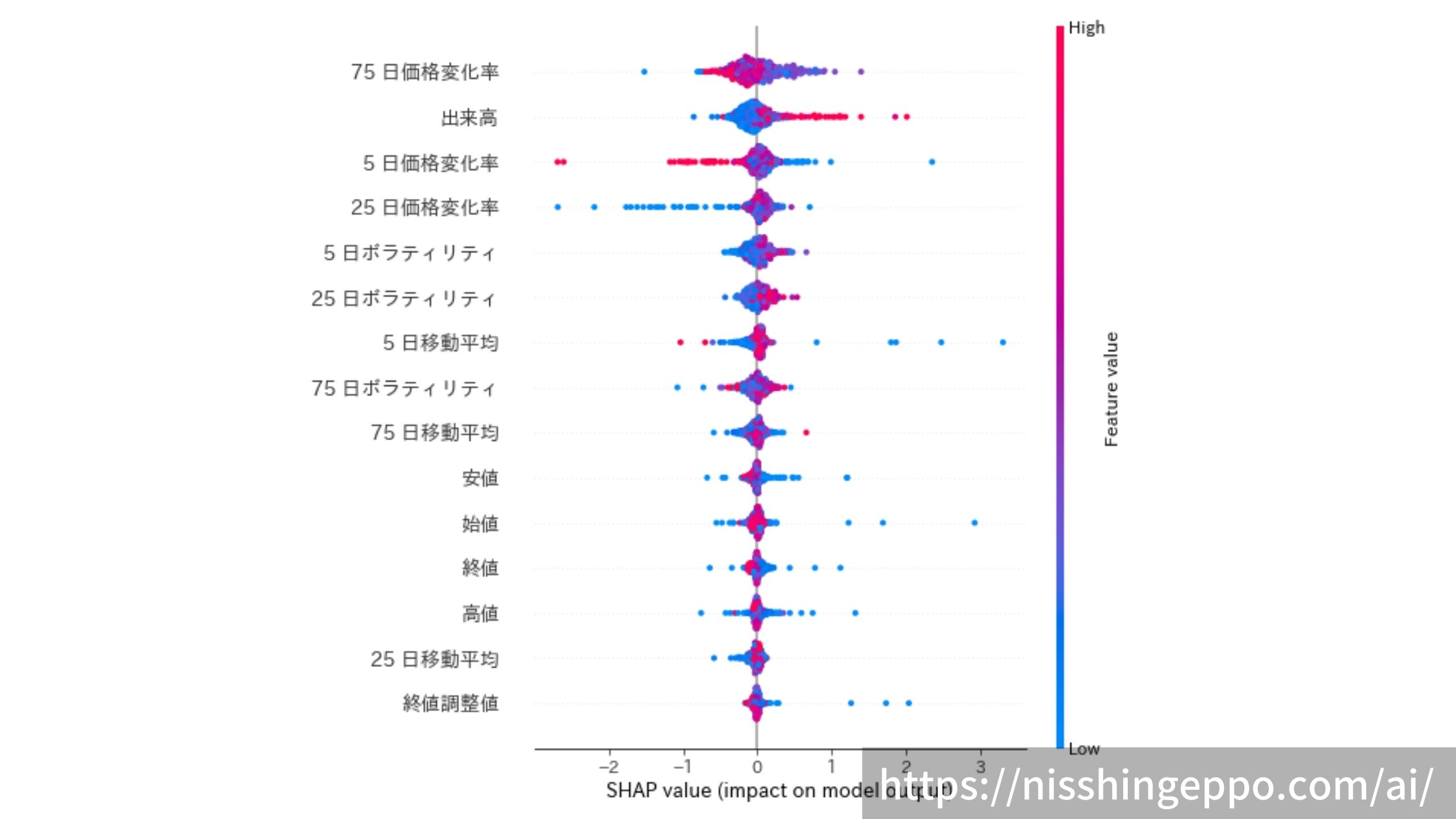
出来高や価格変化率がやはり推論への影響が大きくなっているようです。
まとめ
移動平均・価格変化率・ヒストリカルボラティリティを特徴量として作成してみました。
株価はランダムウォークであり非定常過程ですが、価格変化率では弱定常性になり機械学習で使用できるとのことです。
結果としては今回の検証ではうまく特徴量が使えていないようです。
機械学習で予測できるものの定義が理解できていないので、そのあたりを詳しく調べていく必要があると感じました。
参考文献




コメント