


















- 損失関数とは何か
- よく使われる損失関数とは
- 損失関数のpythonでの実装方法
- 損失関数とコスト関数の違い
損失関数とは
損失関数とは、
です。
「予測値」と「正解値」のズレを表現した指標とも言えます。
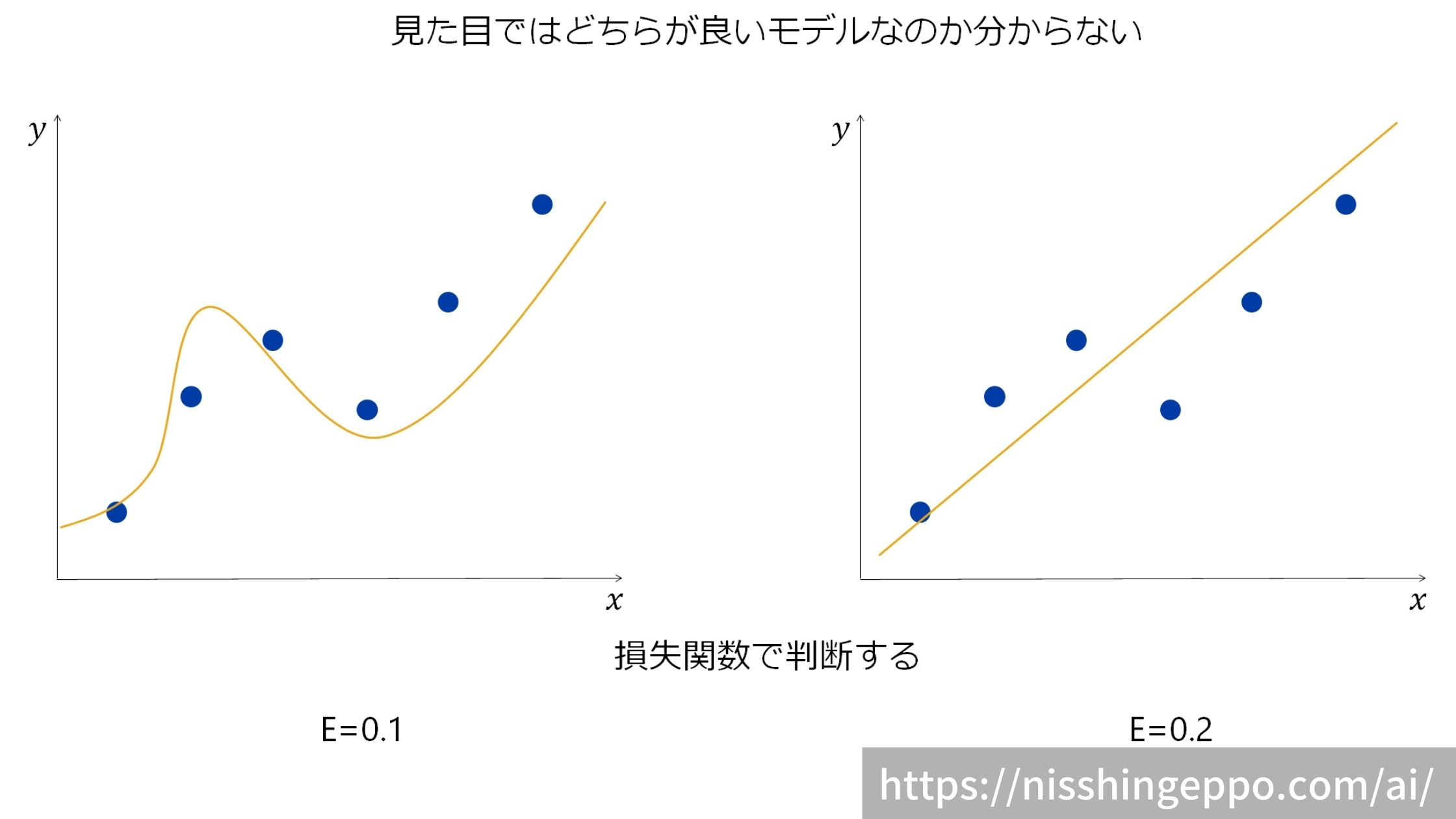
正解を完璧に予測できるようなモデルの場合は損失関数は0となり、予測の精度が悪いモデルほど高い値になるように指標を作成することが多いです。
ディープラーニング(ニューラルネットワーク)では学習を進める際に、損失関数を最小化させるようにハイパーパラメータの値を探索します。
損失関数は任意の関数を使うことができますが、一般的にどのような関数が使われるのか見ていきましょう。
よく使われる損失関数
機械学習では次の損失関数がよく使われます。
2乗和誤差
2乗和誤差では、予測値yと正解値tの差の2乗を合計して2で割ったものです。
数式で表すと次のように表されます。
$$E=\frac{1}{2}\sum _{k}\left( y_{k}-t_{k}\right) ^{2}$$
この損失関数は線形回帰問題でよく使われます。
次のようなデータを例に、2乗和誤差を計算してみます。
$$y=\left[1.1, 2.0, 2.8\right]$$
$$t=\left[ 1, 2, 3 \right]$$
定義式に代入すると、
$$E=\frac{1}{2}\left\{\left( 1.1-1\right)^{2}+\left( 2.0-2\right)^{2}+\left( 2.8-3\right)^{2}\right\}=0.025$$
となります。
pythonのコードで実装すると以下のようになります。
def sum_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)
y = [1.1, 2.0, 2.8]
t = [1, 2, 3]
sum_squared_error(np.array(y), np.array(t))
交差エントロピー
交差エントロピーでは、予測値yに正解値tの対数を掛けたものを合計して-1を掛けたものです。
数式で表すと次のように表されます。
$$E=-\sum _{k}t_{k}\log y_{k}$$
交差エントロピーについてこちらの記事で詳しく解説しています。

損失関数とコスト関数の違い
厳密な定義があるわけではないのですが、
コスト関数は、損失関数に正則化を追加したものという意味で使われます。
損失関数とコスト関数を同じ意味として使っている人もいます。
どういう意味で使っているかは、文脈から意味を判断するしかありません。
まとめ
損失関数とは、機械学習モデルがどれくらい正しく予測できているか評価する指標です。
機械学習では2乗和誤差と交差エントロピーがよく使われます。
2乗和誤差は線形回帰問題で使われ、交差エントロピーは分類問題で使われます。



コメント