


















- AWS Lambdaの作成方法
事前準備
AWS Lambdaを動作させるための環境設定をしておきましょう。
大きく2つの作業が必要です。
IAMロールの作成
Lambdaが他のリソース(S3など)を操作するためには、IAMロールをアタッチして権限を付与する必要があります。
事前にアタッチするIAMロールを準備しておきましょう。
今回はLambdaからデータを保存できるように、LambdaにS3アクセス許可するIAMロールを作成していきます。
まず、AWSサービスの一覧を表示します。
AWSサービス一覧のから「IAM」を選択します。
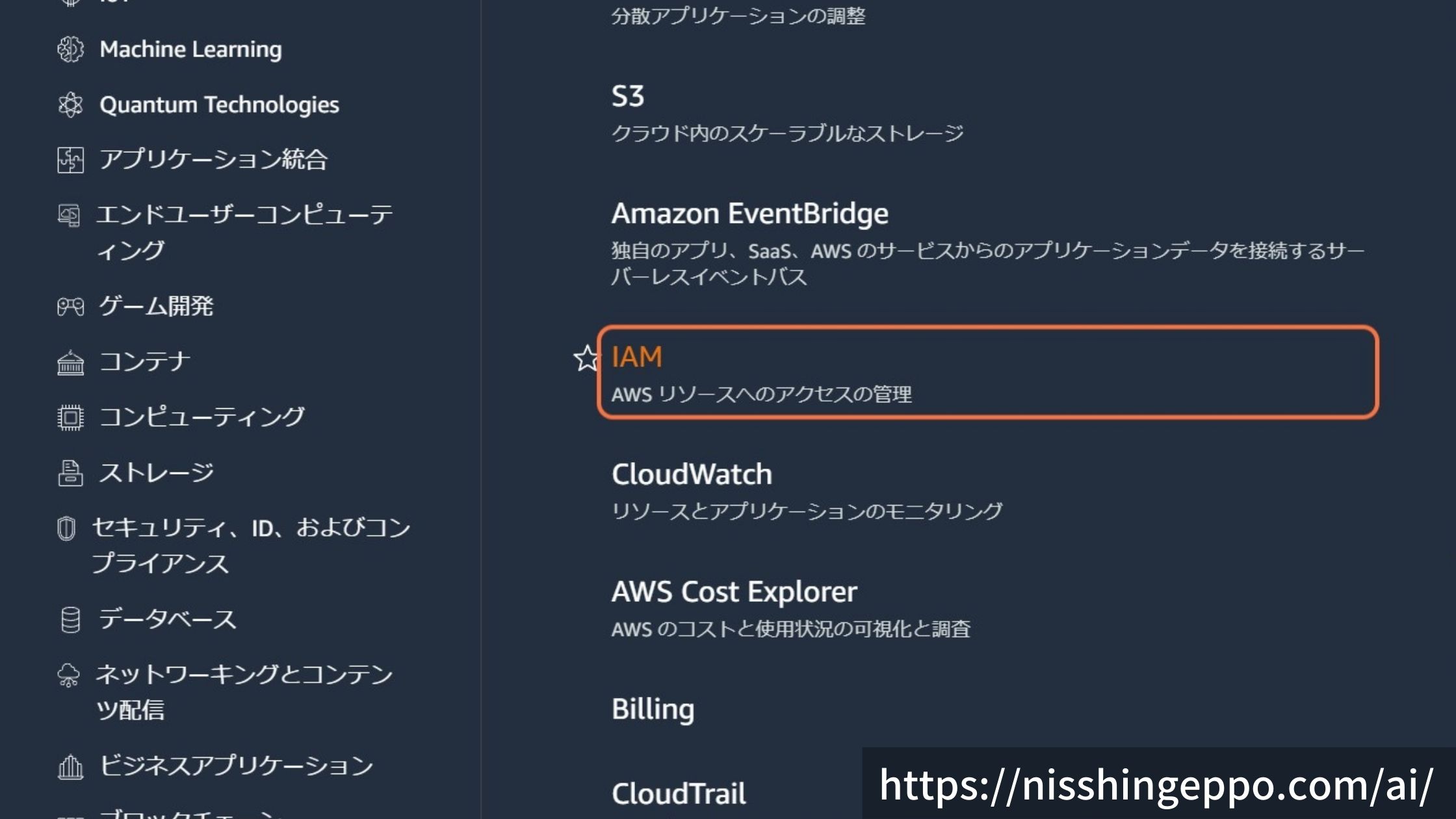
ロールを選択します。
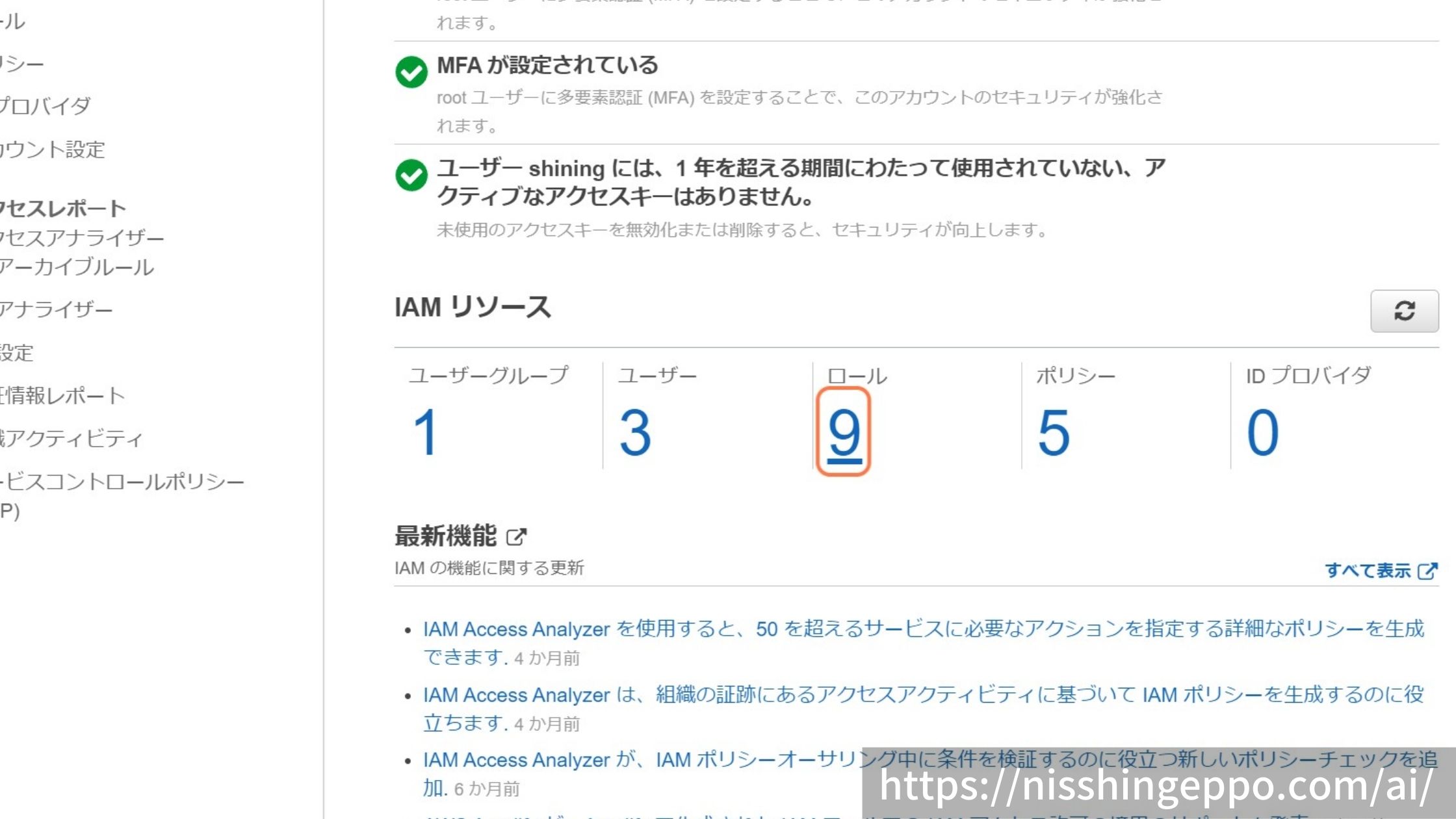
「ロールを作成」を選択します。
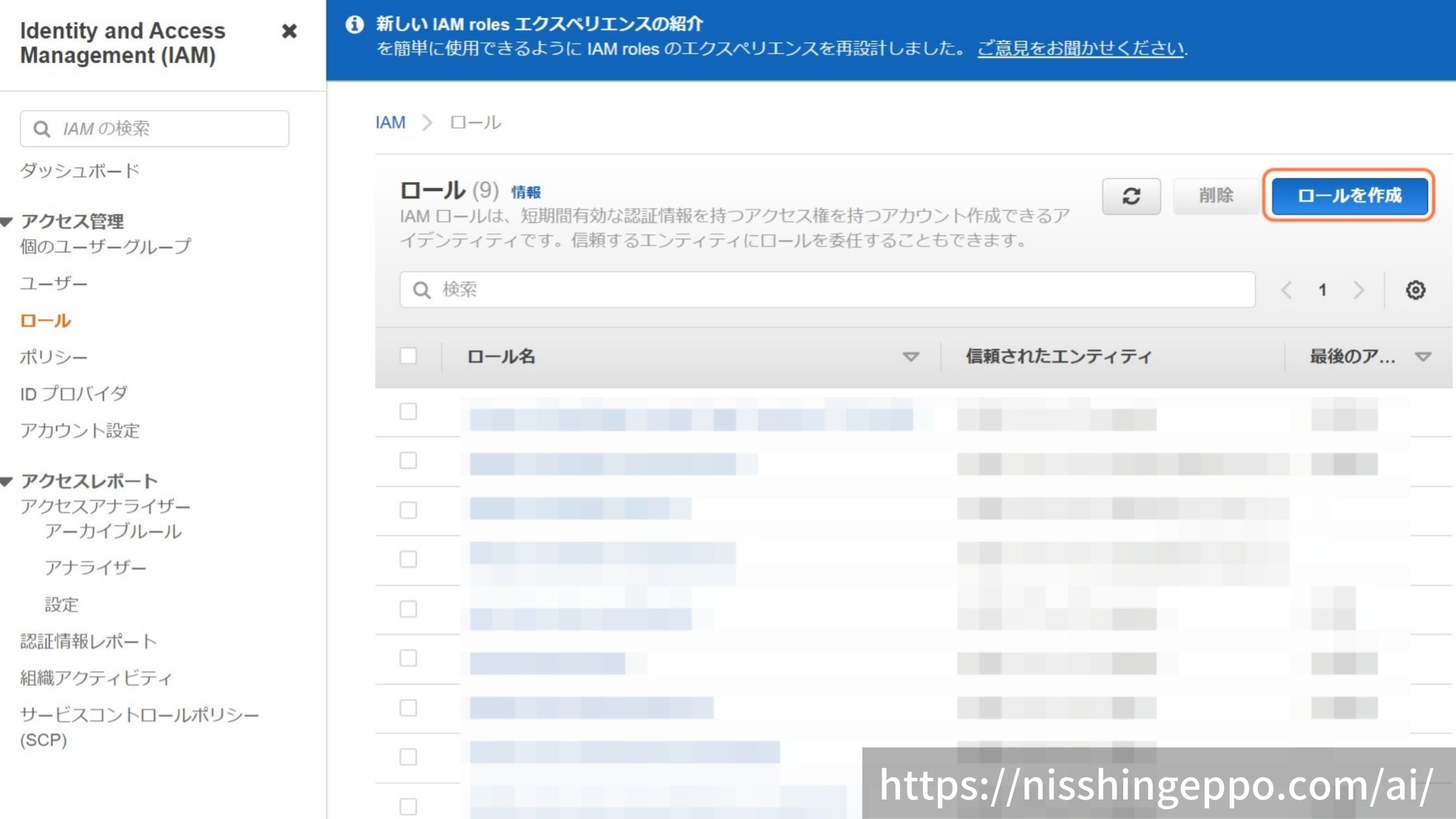
アクセス権を設定するエンティティを選択します。
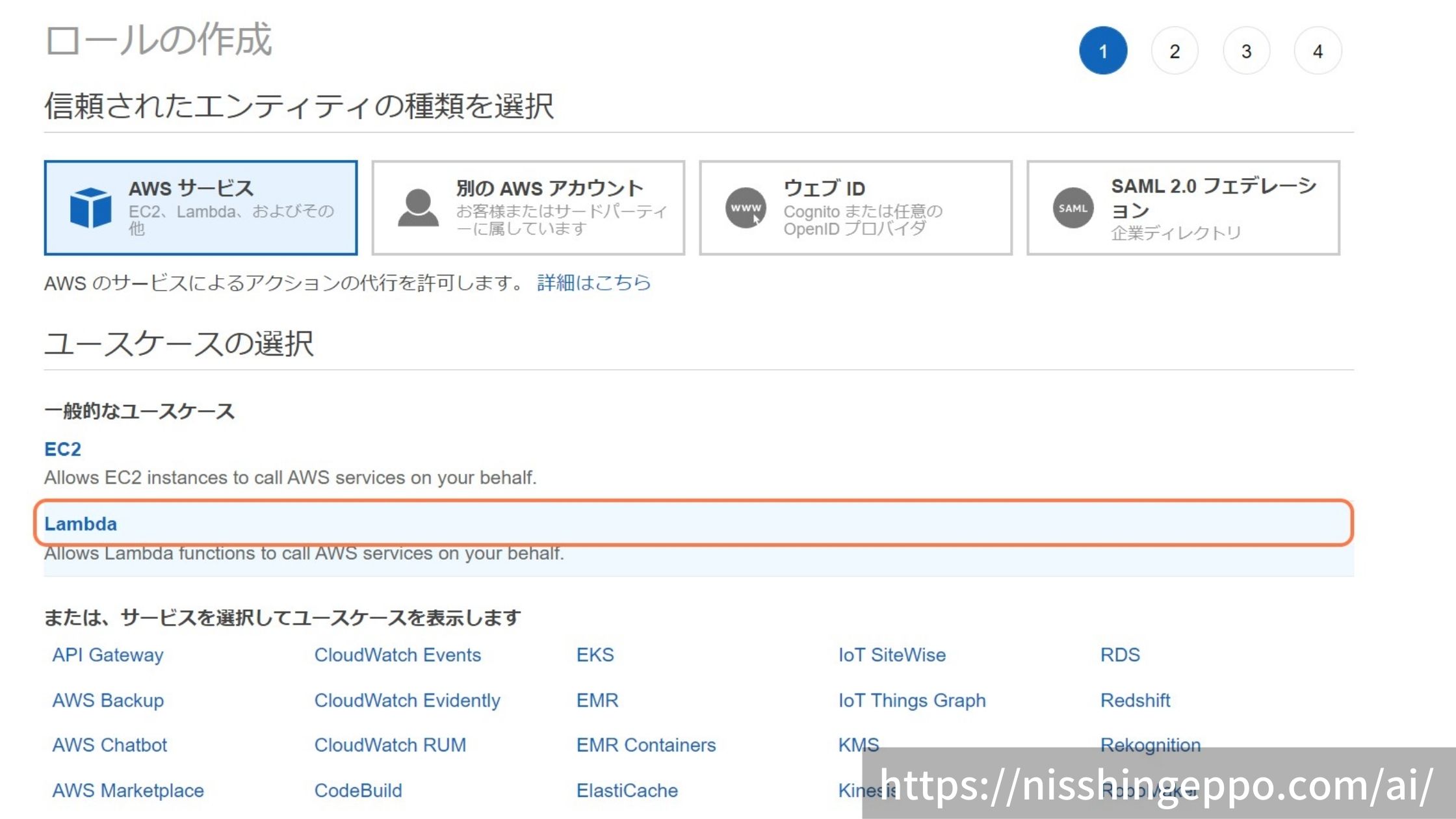
「次のステップ」を選択します。
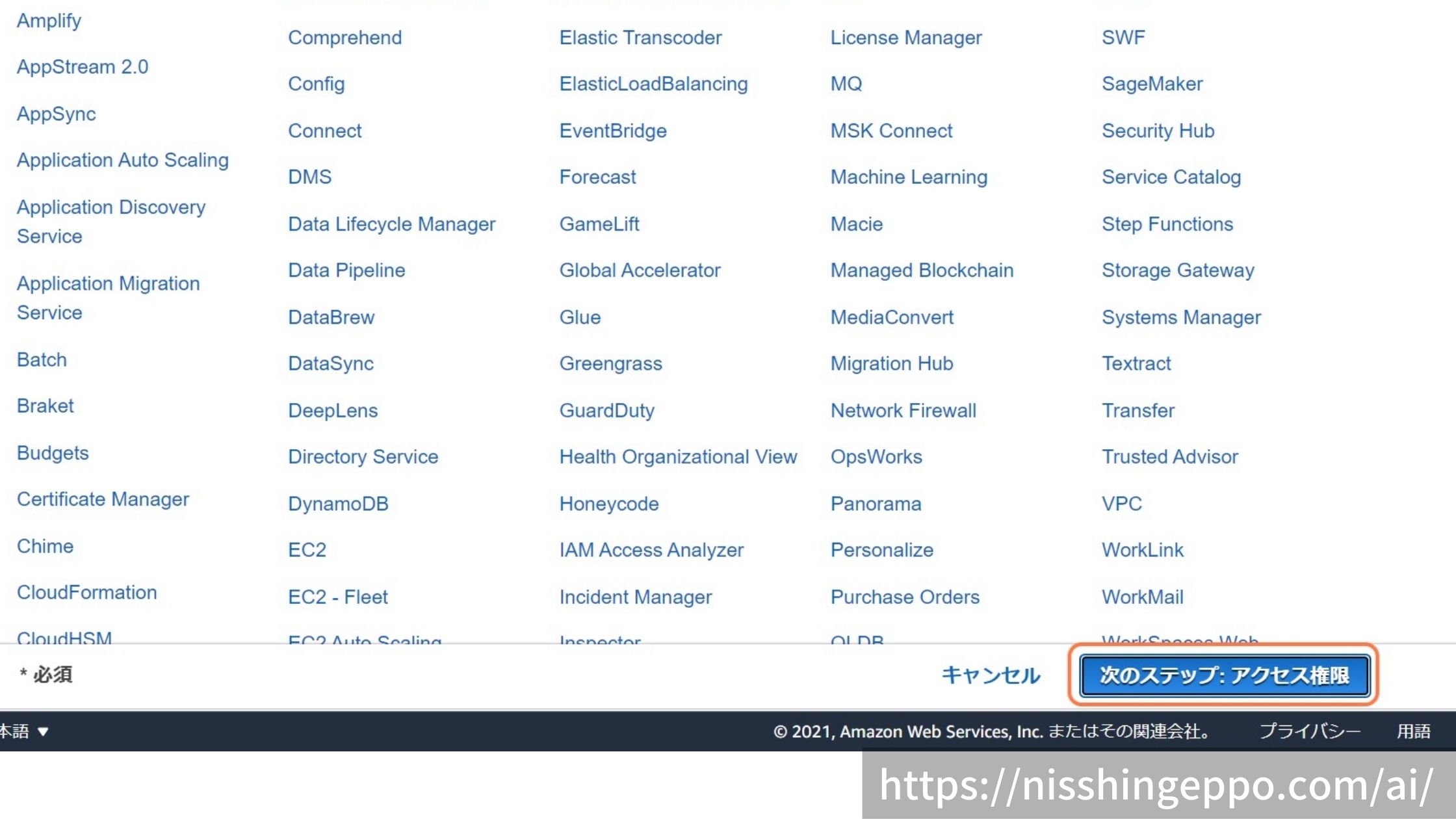
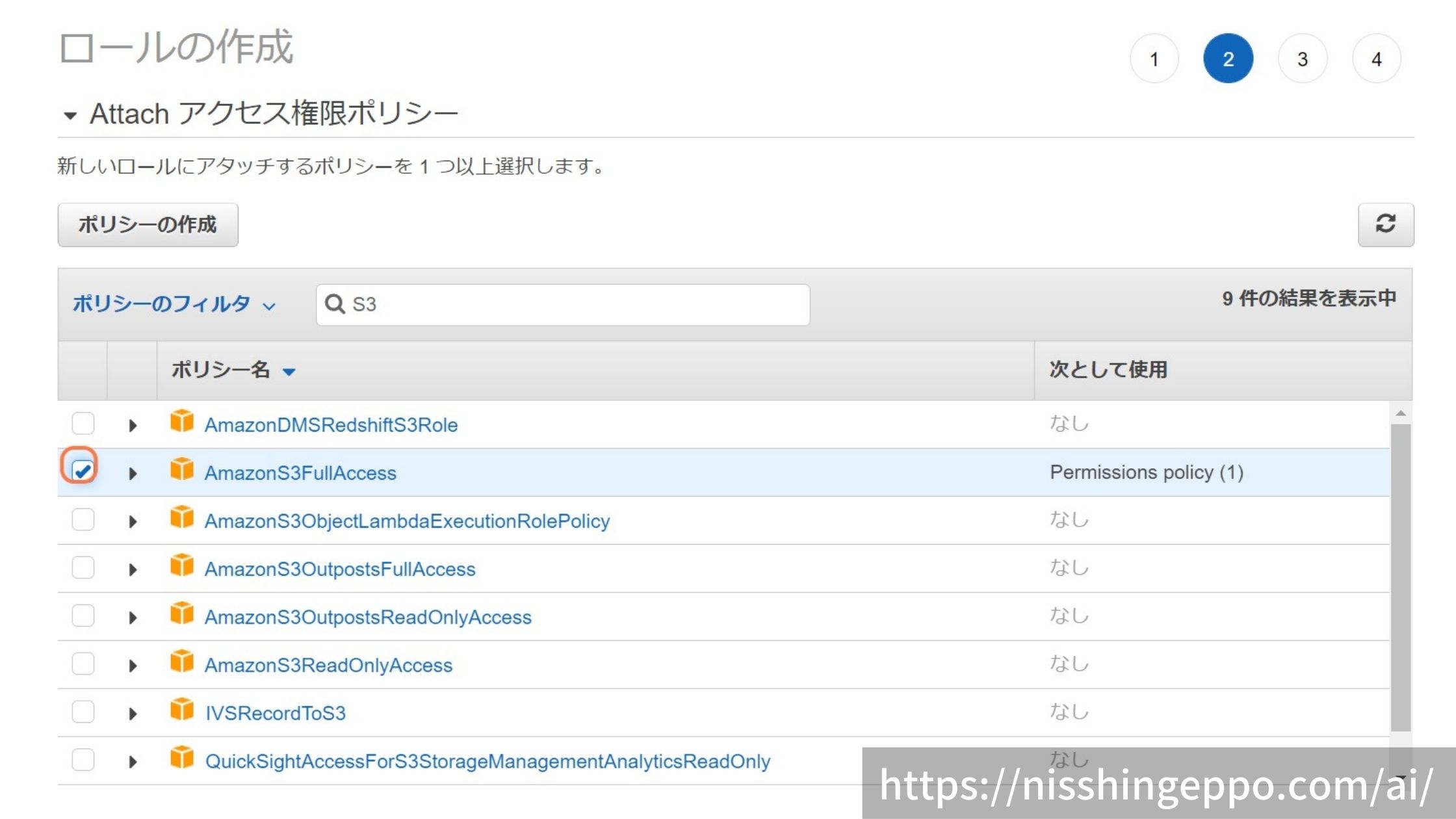
S3にアクセスできるようにアタッチするポリシーを選択します。
今回はアクセスするS3を限定せず、FullAccessを設定しています。
「次のステップ」を選択します。
任意の名称をロールにつけます。
今回は「lambda-S3access」としました。
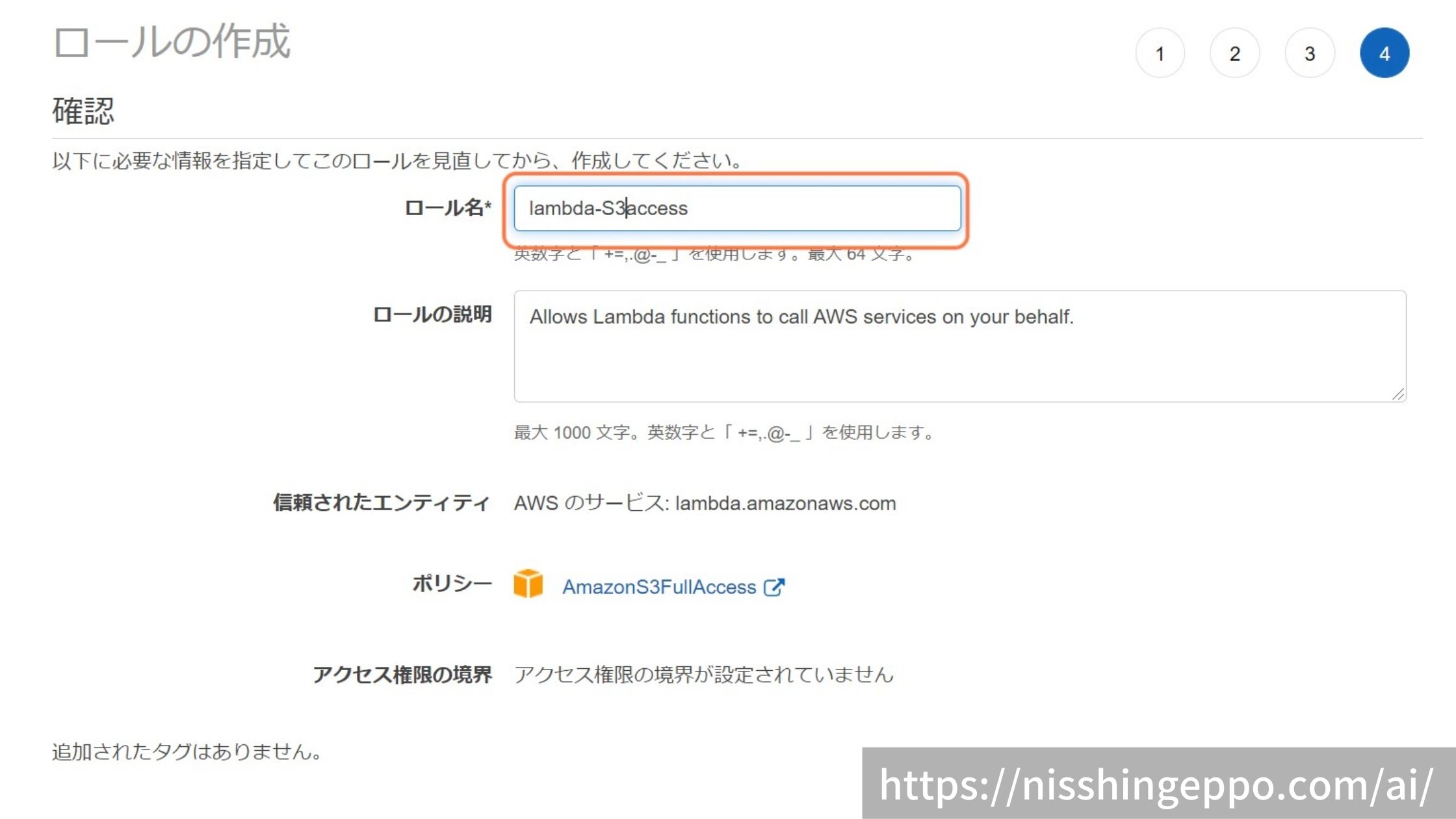
最後に「ロールの作成」を選択すると、新しいロールを作成することができます。
これでLambdaにS3アクセス許可するIAMロールを作成することができました。
Lambdaで使うライブラリのインストール
デフォルトのLambda環境では使いたいライブラリがインストールされていない場合があります。
そのため、ライブラリを導入に必要なLambda Layersを作成しましょう。
Lambda Layersの作成方法はこちらの記事に掲載しています。

lambda関数の作成
実際に動作させるLambda関数を作っていきます。
まず、AWSサービスの一覧を表示します。
AWSサービス一覧のから「Lambda」を選択します。
「関数の作成」を選択します。
新しく作成するlambda関数の名前をつけます。
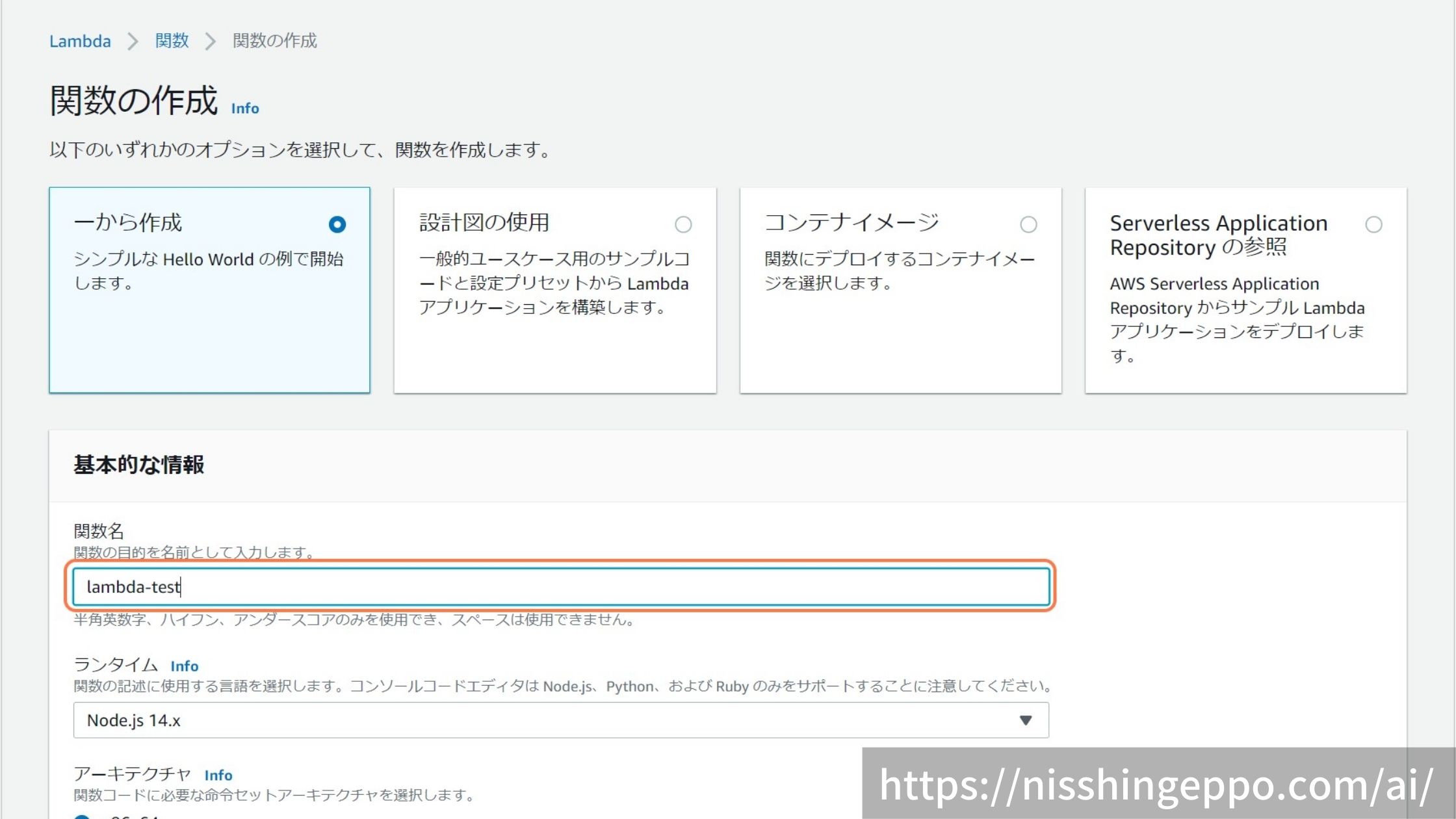
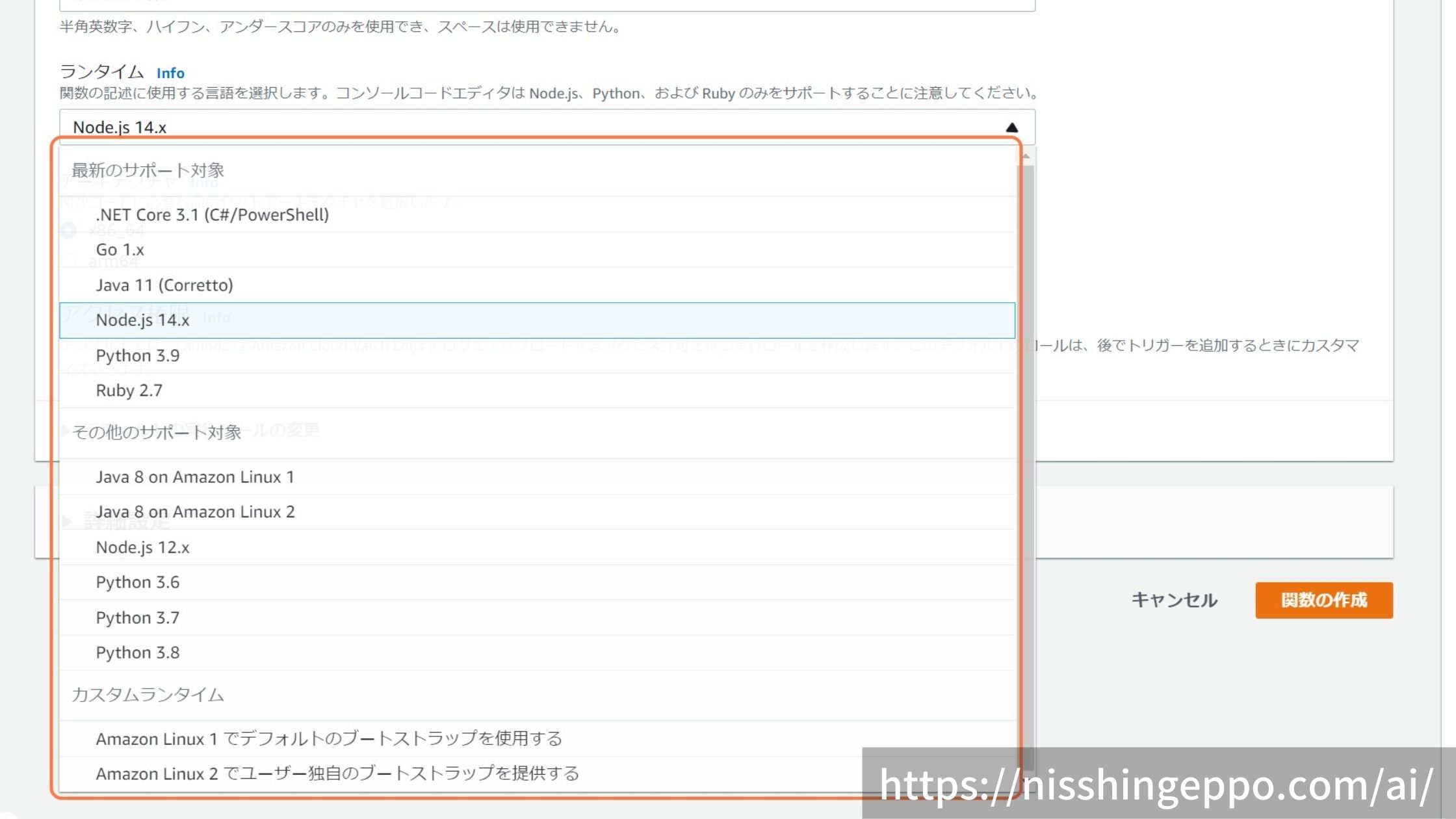
ランタイムを選択し、使いたい言語を設定します。
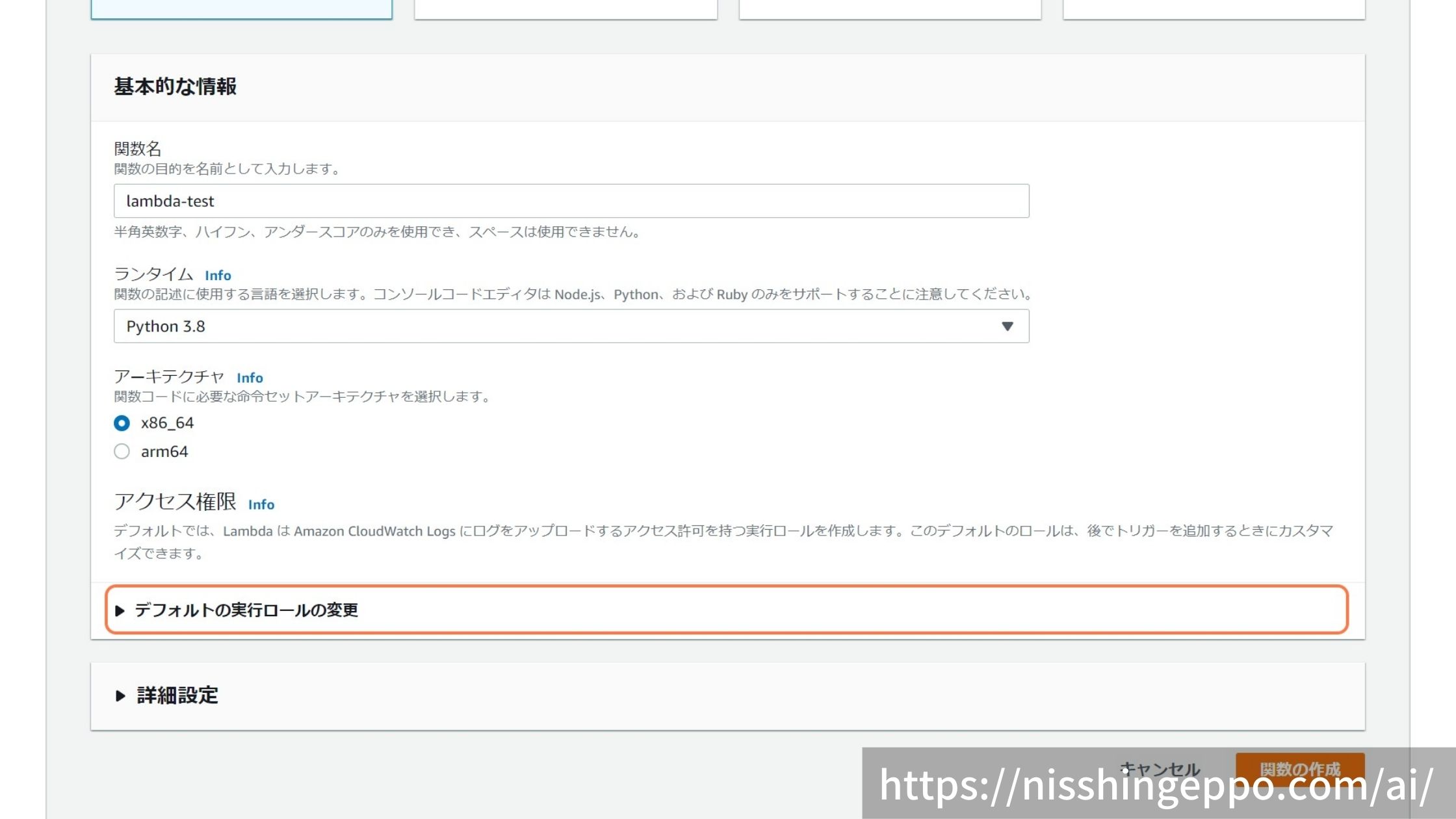
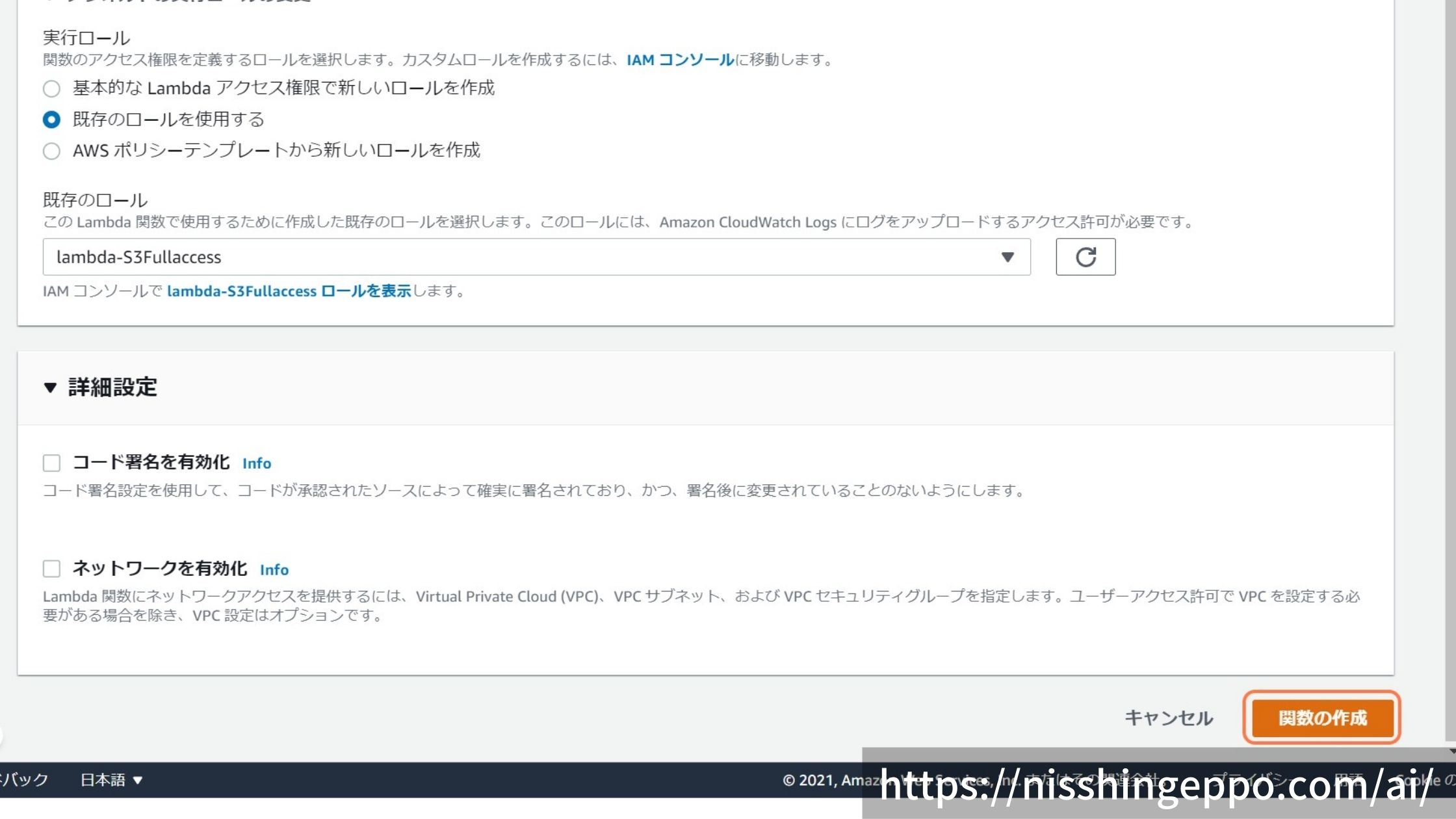
アクセス権の設定をするために、「デフォルトの実行ロールの変更」を選択します。
「既存のロールを使用する」を選択して、先程作ったロール(lambda-S3access)を使います。
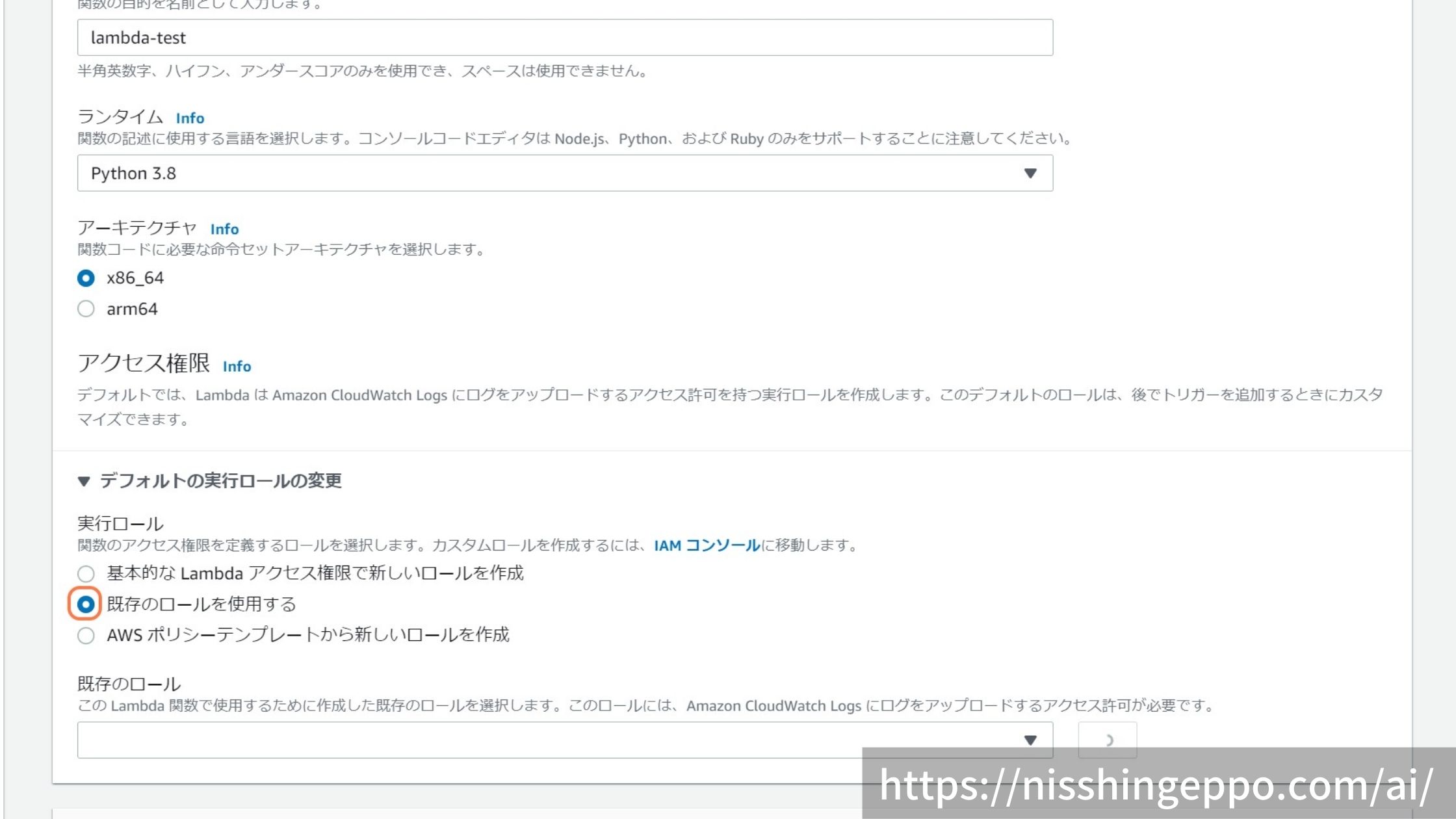
「関数の作成」を選択します。
lambdaのソースコードを作成していきます。
今回作成したのは以下のソースコードとなっています。
受け取った引数をもとにテキストファイルを作成し、S3に保存するものとなっています。
import json
import boto3
s3 = boto3.resource('s3') # S3オブジェクトを取得
def save_s3(code, content):
bucket = 'data-20220101' # バケット名を指定
key = str(code) + ".txt"
file_contents = content # ファイルの内容(string)
obj = s3.Object(bucket,key) # バケット名とパスを指定
obj.put( Body=file_contents ) # バケットにファイルを出力
return
def lambda_handler(event, context):
name = event["name"]
save_s3(name, "hello")
return
まとめ
AWS Lambdaを使ってサーバレスでプログラムを作成する方法を解説しました。
サーバレスにすることで運用時に環境のことを気にする必要がなくなり、アプリケーションに集中することができます。
また、Lambdaは料金が非常に安いのでコストパフォーマンスの優れた実装方法ですので、ぜひ使ってみてください。


コメント